It's a relative abstract measure of case size that's the same across experience levels. A junior and a senior should both be able to agree that a given case is small/medium/large relative to the kind of cases their team usually handles, even if the case would take two hours for the senior and two weeks for the junior. Story points codify small/medium/large into numbers (Fibbonacci is a common choice, like 1, 2, 3, 5, 8, 13, where 13 is often "too big for one sprint").
Mapping story points to time doesn't really work for individual cases because of those different experience levels, it's going to heavily depend on who does the case. Instead, you track story points competed in total for the team for the entire sprint - the different experience levels average out into something consistent, like 30-35 story points per sprint.
"Velocity" is related scrum terminology, and is the mapping of that whole-team measure back to time. A previous team that understood how this worked and stuck to it had those story points per two-week sprints, so we could estimate things months out with reasonable accuracy despite the different skill levels.
I also thought this post was going to be about story points because it's a common complaint from people who don't understand the "different experience levels" part. If everyone on the team reliably took the same amount of time for a given case, then yeah, you could cut it out and just estimate in time. But it's not for that.
There was a small surge in popularity in distributed git issue trackers a bit over a decade ago, and all of them had some sort of problem baked in to the design that made them not very good.
It sounds like there's intentionally no attempt to handle the last one (that this is by devs for devs), and points 3 and 4 might be addressed somehow since it mentions syncing automatically. Does it store data separate from git to avoid the first two?
Thanks for input. Interesting list. A few notes on that:
- Issue state is not tied to commits in the checked out repo. Events live in append-only user-scoped logs and are materialized independently of the checked out branch, so switching branches does not change issue state. This is solved with git worktrees.
- Epiq keeps state in a dedicated state branch and does not put issue data into normal code history. The working branch stays clean.
- Sync uses normal git push/pull semantics.
- Multi-user conflicts are prevented because each user writes only to their own immutable event log file. You never co edit a file. Logs converge state in memory from the combined event stream. There’s no shared mutable issue document being edited.
- The non-developer distribution can be addressed with exported state .md files (with the board as ascii). They are currently not generated automatically, but you can generate them at will. [edit - addition: Considerable effort has also been put into making the tool accessible to non-technical people, so there is auto completion, hints, a command palette with descriptions of each command, arrow key navigation and so on. It is my hope that anyone can pick it up rapidly. And a web interface could definitely be crafted for that usecase]
You don't need to put it on the Web to be able to leverage the World Wide Wruntime.
Epiq looks to be written in TypeScript and distributed as JS via NPM. You know what excels at executing JS? The browser.
If you want to actually address the usability problems—then create a CONTRIBUTING.html—linked from the README, that users are instructed to double-click to open (i.e. launch in the browser on any sanely configured system). From there, they can/should be able to load the project either by pointing to it with a filepicker-based workflow that's the same as VSCode's "Open Folder…" workflow, or by dragging and dropping the source tree into the browser window. If you do it right, then this should immediately present them with a browser-based UI for poring over and interacting with all the Epiq data in the repo—down to the Git commands to execute to integrate changes into the Epiq "database".
It's beyond baffling that so many programmers who are nominally JS developers thumb their noses at writing standards-compliant code and instead insist on coding directly against Node's proprietary APIs.
Indeed, I would use this in a browser (sandboxed) but in these times of exponential supply chain attacks, I'm not `npm install` anything outside a VM, and definitely not globally.
The Browser with its sandbox hardened for the internet is the way to go for any future personal/dx tools that were previously node only.
How can the browser execute git commands from opening a local html file? Maybe if you give the file a different extension and configure an application to run a webserver and open the default browser when the file is double-clicked?
> How can the browser execute git commands from opening a local html file?
It can't. The CONTRIBUTING.html shell would spit out a file and tell the user what Git commands need to be run—just like project READMEs (or landing pages like jekyllrb.com) show which commands will install the tool.
> It's beyond baffling that so many programmers who are nominally JS developers thumb their noses at writing standards-compliant code and instead insist on coding directly against Node's proprietary APIs.
You're talking about node.js projects running on node.js, and you're complaining that it consumes node.js APIs. Strange.
There is no argument or insight in your comment. It's physically possible to type in code that makes direct use of non-standard APIs that work in NodeJS but not the browser. Pointing out that this is so and that there are people who do it is not the same as engaging with the subject of whether they ought not to—which was the point of the remarks you responded to. Previously:
> You're offering a retort to someone who is communicating their position that you ought not do something, where the retort consists of nothing more than explaining that people are doing it. Yes, clearly. But what the person you're responding to is arguing is that you ought not do it.¶ Consider[…]:
> Person A: Here's little advice: don't take up smoking. Smoking is bad for you.
> There is no argument or insight in your comment. It's physically possible to type in code that makes direct use of non-standard APIs that work in NodeJS but not the browser.
You're clearly trying too hard to not understand the issue you're commenting on. For starters, you're purposely ignoring the fact that Node.js is the runtime. Not JavaScript, Node.js. The project is a command line app running on Node.js. It needs to parse command line arguments. It needs to execute commands. It quite possibly needs to access the local file system. It's Node.js, not something that runs on Chrome. This is the very basics. If you do not understand this, you can't even know what JavaScript is. So why are you acting like a white knight for a technology you don't even understand?
I am one of ~3 people primarily responsible for the JS Reference as it appeared/appears on developer.mozilla.org since before NodeJS (or V8) ever existed. I "know what JavaScript is".
I am writing a tool with git tracking. Here's how I tackled these. I store the issues in a work tree inside the git repo called .tasks
This work tree is not included as part of the standard repo
Then I have two commands, a save and restore. These commands create a remote branch inside the git repo called tasks and updates it with the contents of the .tasks work tree. This remote branch only contains tasks no normal code.
Restore takes the contents of the remote branch and downloads it back to the locally created .tasks work tree
Save and restore are manual processes, but the tool I wrote triggers a save whenever a merge to main occurs.
Isn’t splitting code and meta into two repos the same solution here? Like how GitHub tracks your Wiki in a separate repo (which you could repurpose for your issues, even).
The ones in those first two bullets made issues part of the repo so you'd clone/push/pull updates automatically with the normal git commands. They were trying to reduce friction with usage: Fewer new commands to remember/use, local data so the commands were instant like "git commit" or "git show" are, and automatic syncing but only when the user was already doing it so there wouldn't be unexpected hangs if the remote was inaccessible for some reason. Putting them in the same repo also meant since they came along with every normal git clone, every repo had a copy regardless of if a specific user had the tool or not, so switching between hosts would never be an issue and would automatically be supported without having to update however the two repos were linked.
The one that tied issues to specific commits I think even portrayed the different-states-in-different-branches as a feature, that for example you could easily tell at a glance whether a bug had been fixed on the branch you're on or not. This was also the era when people were figuring out complex branching strategies like gitflow, where that would be a reasonable thing to be uncertain of.
Like I said the problems were part of the design, not incidental, the tradeoffs just ended up not what people wanted.
Also something else I didn't mention before, all of these were command-line, not TUI. I have no idea how that would've changed the result. For example I could imagine automatic background syncing actually being reasonable, sidestepping some of the issues the command-line ones had to work around.
Out of things listed there, I see some as positives rather than negatives, but, specifically, wanted to reflect on:
> No non-developer UI for project managers to see or comment on issues.
Strategically, I'd prefer this over anything that offers non-developer UI. My experience with any tool that offers non-developer UI for developer-related activities was overall infuriatingly negative (think Jenkins, JIRA, Github and the likes etc.) Because these UIs will usually expose the underlying functionality in a bad way that will create pathologically bad practices that will require the developers to accommodate the lowest common denominator.
Here's one example: Github or GitLab PR management interface. Before this became "standard practice", PRs used to be deal with from the interface to Git chosen by the developer. It allowed more freedom of editing and communication, but, most importantly, it didn't lock the developers into a few selected choices of reconciling the new changes with the existing code.
GitLab, for example, doesn't even offer the only good way to do that: there's no way, using GitLab interface to rebase the suggested changes on the target branch. All the options it offers in UI are wrong. And yet, companies, like the one I work for, make it a corporate policy to work exclusively through this garbage UI because they make their OPs / IT teams design workflows around it.
As an aside: if a project manager cannot use Git, they shouldn't be a project manager. There are some job requirements that one must meet in order to hold a job, and using the most popular VCS should be one of them. This is just as true as it is true for developers: if they don't know / can't use Git, they shouldn't be in that role. The manager's ineptitude shouldn't be an excuse to make / adopt cruddy software.
> Imagine you get asked to build something ambitious, and you say:
> “Sure, I’ll have the Speed version ready in 3 days. Then the Scale version in about 6 weeks.”
> They get what they want, speed and momentum. You get what you want, observation and design.
Except that 6 weeks is now blocking the next thing and you'll be pushed to drop it. So this doesn't really solve anything.
I was kind of hoping at the end they'd suggest getting the non-developers involved more so they can experience the pain points they're creating. Not entirely sure how that would work though.
For anything Lucene-based (Elasticsearch, Solr) this was a problem where some of the indexed data had to be transformed for another type of query to be efficient, and it put the transformed data into the Java heap then never released it. I think it was indexed data for searching was read straight from disk and was fine, but analysis queries needed the transformed version?
At some point they added the docValues configuration option per-field to do the transformation during indexing and store it to disk instead, so none of it had to be stored in the heap. Instead what you're supposed to do is rely on the OS disk cache, which handles eviction automatically, so you can run with significantly less memory but get performance improvements by adding memory without having to change any configuration further.
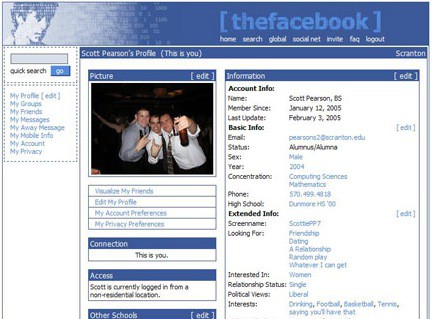
"Groups" is New Facebook, the replacement for the Network pages.
Used to be there was a whole section of the site meant for connecting with people at the same college/university as you, that you were automatically included in based on your email domain. It had a calendar and events and was geared towards real-world interaction.
You're thinking of something else, Groups didn't exist until 2010 (though I thought it was a bit earlier, like 2008 - I thought they came out about the same time the Network pages went away, while I was still in college): https://www.theguardian.com/technology/2010/oct/07/facebook-...
I do remember Friend Lists were much earlier though.
> You're thinking of something else, Groups didn't exist until 2010
No, I'm not thinking of something else. You are assuming that when I say "groups", I'm thinking of the feature called "Facebook Groups" in your link, which is a stupid thing for you to assume.
> e.g. to approve a MR you need to click a button that is actually a menu
I think you're referring to the "Your review" button in the upper-right that's not always there, but there's a plain "Approve" button on the Overview tab that doesn't open any menu and is always there.
{kind=link}
Mapping story points to time doesn't really work for individual cases because of those different experience levels, it's going to heavily depend on who does the case. Instead, you track story points competed in total for the team for the entire sprint - the different experience levels average out into something consistent, like 30-35 story points per sprint.
"Velocity" is related scrum terminology, and is the mapping of that whole-team measure back to time. A previous team that understood how this worked and stuck to it had those story points per two-week sprints, so we could estimate things months out with reasonable accuracy despite the different skill levels.
I also thought this post was going to be about story points because it's a common complaint from people who don't understand the "different experience levels" part. If everyone on the team reliably took the same amount of time for a given case, then yeah, you could cut it out and just estimate in time. But it's not for that.
reply