I hope (but am skeptical) that folks look at the overall failure of ipv6 from a deployment perspective to understand the root causes of why it failed (some may think "failure" is too strong a word, but I remember v6 being "just around the corner" in 2000, yet in 2019 I'm still connecting to a GCP database with v4).
Coming up with a solution that looks like a huge technological advancement, with no real respect for the motivations or incentives of those who'll need to implement and use it, is a fairly common occurrence in tech and something engineers should be trained to guard against.
- There is a lot in IPv6 that is different from IPv4. Ignoring if those changes are good or bad, it does make the transition harder.
- IPv6 was promoted way before there was demand. To some extent it is good to prepare people (and vendors). But it does create the impression that IPv6 is a failure
- Demand for IPv6 is highly asymmetrical. The party that is out of IPv4 addresses needs IPv6. But everyone who has enough IPv4 space has no reason to care.
When IPv6 was first promoted, there basically was no IPv4 market. You would just go and get more IPv4 space when needed. For the last couple of years we now have a mature market for IPv4 addresses.
It is possible to buy IPv4 addresses, but prices go up. At some point it becomes interesting to try to move traffic to IPv6.
More issues with IPv6 that are relevant for me as a techie:
- Memorising an IPv4 address is about as easy as memorising a phone number, which is to say, fairly easy. I remember the iPv4 addresses of both my rental servers, every device on my home LAN, a bunch of public DNS servers if things go wrong, ...; there's no way I'm going to be able to do that for IPv6.
- At least last time I tested it (more than 10 years ago now), the greater length of IPv6 headers had a quite measurable adverse impact on transmission latency of small packets (online gaming, remote shell...)
- Why do people keep treating "you get your own unique IP address when browsing" as if it were an advantage? The way I see it, NAT and IP address reuse (especially together with some European countries' laws stipulating the address->identity mapping must be deleted within some time period) are the currently most widely rolled out privacy technology. Somewhere downthread, they talk about how Belgian police is trying to prevent ISPs from putting more than 16 customers behind the same internet address. Since I can hardly say everything I do on the internet is perfectly legal, what's bad for Belgian police is probably good for me.
Your point (and reply) about memorization was good. Yes, I'm not constantly remembering "210.40.138.43" but enough tech people need to remember some of these things - for debugging, support, etc - that IPv6 is painful. Asking someone to verify an IPv4 in a dialog setting is doable - an IPv6 is not.
I've maintained for 2 decades that simply adding another 2 slots for 0-255 would have opened up a greatly usable amount. Every current v4 - 210.40.134.34 - would also be 0.0.210.40.134.34, but we'd have another 65000 groupings of 4 billion addresses to allocate as needed, and a transition would have been far easier (smaller space, less processing, easier to think about, etc).
I use copy and paste for both IPv4 and IPv6 addresses.
I understand where you are coming from by adding a few more bytes to the address scheme but one of the things IPv6 was designed for was massive address aggregation which means really short routing tables. Your 192.192.168.168.0.0 (say) scheme does not go far enough. Also, your scheme needs to be efficient in the world of bits and bytes and I don't think it is. Your scheme would probably need to be 64 bit to start with and not 48 bit because silicon, etc doesn't work like that.
However that simple routing scheme was blown out of the water by private addressing - ie get your own ISP independent address range. When you change ISP you end up with another prefix and hence all your addresses change. All addresses. So you buy your own range (about £3000 set up and £3000 per year from memory. You also need an ISP(s) to route it and if more than one then a BGP peering arrangement.
Another wrong in the name of IPv6: 64 bit IPv6 prefixes from an ISP means you can only have one subnet. No way to put your dodgy IoT stuff on its own VLAN.
I have a pretty good ISP - I get a /56 but the original idea was /48 for everyone. I only have 256 subnets available. With /48 I would have say 256 x 256 subnets which would be ideal for my family. With /56 I have very little elbow room.
Each subnet (/64) is 18,446,744,073,709,551,616 addresses - which is nice.
> Another wrong in the name of IPv6: 64 bit IPv6 prefixes from an ISP means you can only have one subnet. No way to put your dodgy IoT stuff on its own VLAN.
Can't your router handle carving up a subnet just fine?
A lot of self-assigned IPv6 networks just tack on the device's 64-bit MAC address on to the end of some 64-bit network prefix. So if you're going with self-assignment of IPv6 addresses then you will have difficulty if your assigned prefix is already 64-bits, since you can't really use any of the 64-bit suffix bits for your own network.
The mechanism is called StateLess Address Auto-Configuration (SLAAC) [0]. It removes the need for DHCP, and the determinism is very convenient. There are of course privacy downsides for deterministic addresses that are globally routable, and that's where SLAAC privacy extensions come in [1].
More precisely, disabling the autonomous addressing flag in the router advertisement packet allows you to completely control the addresses which will then only be handled by DHCPv6, which allows you to slice a /64. But that means no v6 temporary addresses for anonymisation, which might be exactly what you want in a managed network/corporate scenario which requires liability tracing.
That only helps in making the addresses seem more familiar but does not solve any of the other problems IPv6 solved. You would still need two separate protocols anyway because there is no backwards compatible way to route that.
NATs break end to end. This might be acceptable in a HTTP(s) only world though.
Of course, some people aren't only using the Internet for browsing.
The Internet of things will end up needing unique endpoints, and NAT does not play will with those either.
India has a lot of people, and quite a few of them will be IPv6 only (or behind a very degraded carrier grade NAT). If you are talking to customers/clients/vendors there, assume you need IPv6.
Memorising IP addresses isn't done in any larger scale network, you use DNS.
NATs work well at about the scale of a single household, beyond that, they keep making things worse.
> NATs break end to end. This might be acceptable in a HTTP(s) only world though.
I was always curious about this argument -- do you mean that NAT elimination will allow any two arbitrary devices to communicate with each other?
I would think that even in IPv6 world, the firewalls would still be a necessity. Most ISP would continue shipping routers with stateful firewall enabled by default (to prevent internet exploits), so any peer-to-peer software would still have to deal with UPnP/STUN/TURN. Sure, the STUN protocol will be simplified a bit because it would not need to worry about IP changing, but it would still be way more complex than just a simple connect() call.
Note that the situation maybe better in some cases -- like for India or for cell phone networks -- but there would still be enough people behind the firewall to make arbitrary incoming connections unreliable.
Related: the privacy extensions seem to be a pretty bad idea. I have no idea how would I set up a firewall to say "allow incoming traffic to my main laptop, port 22222" if it's IP address always changes. Ideas like "disable privacy extensions" and "filter by MAC" have their own significant downsides.
- If you go around memorising addresses then you are doing IT wrong in general. So many things depend on DNS (not just A records) that punching in IPs by default is a bad habit. Browsers will keep on enforcing SSL/TLS more and more until the point where typing in an IP address into the URL bar will be as painful as using the web GUI for say an elderly HP switch is right now.
- In general latency is not affected by header lengths these days. In some cases, networks are prioritising IPv6 for the opposite affect. In other cases ISPs have dropped their entire IPv6 support without noticing for quite some time. sigh
- The addressing scheme in use should have nothing to do with your privacy. Yes NAT does accidentally hide you a little bit. However I can fingerprint your browser instead, for example. I'll trade easy SIP n RTP over NAT any day.
Now, for my gripes:
- Try doing multi WAN effectively over IPv6 without PI and a routing algorithm, or NAT
- Try changing ISP (new addressing everywhere)
The second gripe I currently work around with RFC 4193 - Unique Local IPv6 Unicast Addresses, the first one I whine about and will probably use NPT (wholesale NAT for IPv6)
> - If you go around memorising addresses then you are doing IT wrong in general. So many things depend on DNS (not just A records) that punching in IPs by default is a bad habit. Browsers will keep on enforcing SSL/TLS more and more until the point where typing in an IP address into the URL bar will be as painful as using the web GUI for say an elderly HP switch is right now.
Most of the things I do with memorised addresses have nothing to do with the browser or HTTP. (Mind you, though, the moment a browser won't let me access a bare IP, I'm switching away from that browser.)
> - In general latency is not affected by header lengths these days. In some cases, networks are prioritising IPv6 for the opposite affect. In other cases ISPs have dropped their entire IPv6 support without noticing for quite some time. sigh
I wondered if this may be the case; I may need to rerun some tests.
> - The addressing scheme in use should have nothing to do with your privacy. Yes NAT does accidentally hide you a little bit. However I can fingerprint your browser instead, for example. I'll trade easy SIP n RTP over NAT any day.
A website I navigate to may, but how will the carrier fingerprint my browser?
All in all, it seems like we are talking about very different threat models to privacy/security. You are worried about the likes of Google and Facebook profiling you, whereas I am worried about the likes of $intellectualpropertymonopolist sending me a $20k bill for identifying me in a torrent, or experiencing a nasty surprise at $nationalborder (or at home, [1]!) for something I said on an internet forum.
(This does not seem like an abstract or overblown threat to me; I've seen 2 out of the 3 things above happen to friends and even one schoolmate more than 2 times.)
Most of the things I do with memorised addresses have nothing to do with the browser or HTTP. (Mind you, though, the moment a browser won't let me access a bare IP, I'm switching away from that browser.)
Me too. Wireshark, nmap and co are in regular use in my job. All browsers are playing nanny, more and more apart from the likes of Links (which I also use quite often). A lack of https is already flagged and I suspect that things will get worse in this regard. Links2 has saved my bacon many times in the past so you may enjoy it 8)
You are worried about the likes of Google and Facebook profiling you
No mate. I'm CREST accredited: I'm not worried about G and F profiling me - I know they do. However I also know that my choice of addressing scheme does not affect my privacy whatsoever. A carrier can use metadata to derive loads of facts about your usage even if you are connecting to the oher end over say https. NAT will save you from some silly firewall screw ups but not much else. A VPN can help but is no silver bullet either. If I really put my mind to it I could probably make myself near enough anonymous with enough use of proxies, VPNs and TOR but I'm not too sure about that!
I too am from the UK and have seen silly overreactions such as your [1] link. However, this is the world we have nowadays and in our case we have a horrific level of CCTV pointed at us as well as some pretty impressive levels of IP traffic mining. We also have the rather unpleasant RIP Act and a few others to belie our supposed liberal way of life in the UK. You do have to be careful what you say nowadays, within reason.
Well, my assumption was always that in a scenario such as: ISP makes me share my public-facing IP with 15 randos -> I get on a torrent for Sony Corporate Secrets [full pack] [2018].zip -> Sony's legal department connects a honeypot and harvests all IPs it sees on it and sends out subpoenae to identify everyone who is in a friendly jurisdiction, the circumstance that I'm NATted by my provider will actually do nontrivial work in reducing the probability that I am ultimately identified in a legally actionable way (especially if it were to take Sony a while to process its data). Is this not accurate?
> - If you go around memorising addresses then you are doing IT wrong in general. So many things depend on DNS (not just A records) that punching in IPs by default is a bad habit. Browsers will keep on enforcing SSL/TLS more and more until the point where typing in an IP address into the URL bar will be as painful as using the web GUI for say an elderly HP switch is right now.
This heavily reminded me of the good old Night Watch essay[1]. You can punch DNS names into the address bar on a browser, because someone out there traded normal sleep schedules for the tremendous opportunity to think about BGP trees, netmasks, and other exciting arcana.
> If you go around memorising addresses then you are doing IT wrong in general. So many things depend on DNS (not just A records) that punching in IPs by default is a bad habit.
If you are debugging network connectivity, then I have a tough time believing it’s possible without typing in a few network addresses.
This is easily solved with mDNS/Avahi. I had the same gripe years ago, now my hosts advertise their own records or even on behalf of others without running a NS.
It’s just a bit of a pain to maintain if the only thing you care about is connecting to server nr 192.168.0.x
I could certainly do it, but there’s 5 services in my house I’d care to connect to, and remembering 1-5 is just as easy as giving them all names. The marginal gains are very low.
It's actually pretty easy. I was able to set one up when I was a teenager, almost 25 years ago, in the early days of the commercial Internet. It is even simpler now.
You can buy a DNS domain for a few quid per year or you can use a dynamic DNS service such as freeDNS for err free.
If you go around exposing services on the internet then you should know how to do it properly. If you can get a name on it then you can put a SSL certificate on it (cheers Lets Encrypt).
If you have a SSL cert on it then you can be fairly sure you are talking to your gear and not a MitM if you take other precautions.
I absolutely do have a LE SSL cert for my home router and all my home web sites. pfSense has a ACME and dynamic DNS client for many services and HA Proxy built in. What more could you want!
With IPv4 you don't HAVE to buy a domain for your local network. You can do just fine with IP addresses. With IPv6, you probably will need to just to make it sane. That adds a whole new step, and a complex one that most people (general public) won't know how to do.
To be fair, most of the general public doesn't know what an ip address is.
I'm in the group that you're speaking of—I have a personal server set up that I can log into remotely, but the prospect of setting up a domain and TLS is very daunting. But, I don't think people like me are all that common.
> Why do people keep treating "you get your own unique IP address when browsing" as if it were an advantage?
The original tenet of the internet pretty much hinged on the idea that every person with a computer can host/self-publish information as well as consume other people's information in a distributed way. They will not have to depend on a centralized publishing authority.
> Why do people keep treating "you get your own unique IP address when browsing" as if it were an advantage? The way I see it, NAT and IP address reuse (especially together with some European countries' laws stipulating the address->identity mapping must be deleted within some time period) are the currently most widely rolled out privacy technology. ...
Although IPv6 doesn't have NAT, per se, it does have Network Prefix Translation (NPTv6). And some VPN services (FrootVPN and Perfect Privacy, for example) have already implemented that.
I have no real first hand knowledge of this, but I have wondered if part of the reluctance of ipv6 is the fact that many of the "powers that be" use ip addresses to identify and group traffic and other activity from multiple devices. They also use ip addresses to block scrapers (both Google and Amazon do this heavily).
With ipv6, an IP address can be completely disposable. You could scrape Google search results all day long and use a different address for each call.
Heck, you could completely proxy search results in real time and create your own search engine, secretly using Google as your backend while injecting your own ads.
If you try to do this at scale you'll find you won't get transit anywhere. Any AS will drop routes from you when Google looks their way. If you think you can ignore them, they'll just threaten upstream. You'll be cut off in hours.
Wouldn't you be bound to a specific subnet dedicated to you? Or how does it work? Can you really just propagate to the world at any time "I am now baba:fefe:..."? Don't backbone routing tables get crazy mad verbose that way?
It would be a random address from a given subnet, yes. Basically the privacy, tracking and banning implications of this are more or less the same as they are with v4+NAT, with the v4 public IP mapping to the v6 subnet.
Note that there's still no way to map a subnet to a person, just like there's no way to map a public v4 address to a person.
Huh, are you implying that with IPv6, the ISP can place multiple unrelated people in the same subnet but not coordinate with them regarding what address from the subnet they use? How does this work from a routing perspective? What if two people pick the same address?
On the other hand, if the ISP ultimately does hand out the address in the subnet (and the end user can merely ask it for a new one), the ISP can retain a record of this, which together with the server-side data can be used to unambiguously deduce who accessed what, whereas the equivalent information in v4+NAT is insufficient without also logging everyone's connection metadata. It would therefore be more appropriate to say the privacy, tracking and banning implications are the same as dynamic IPv4 without NAT, where you can likewise request a new address from your provider at any time.
Normally what happens is: you request a prefix from the ISP (call it a /56, which is 256 subnets of /64 size each), then you pick one /64 from the prefix and use it for your network. Your computers then assign themselves randomly-selected addresses from the /64.
The prefix might be 2001:db8:1:2300::/56, the first network 2001:db8:1:2301::/64, and the machines on that network 2001:db8:1:2301:random:numbers:go:here.
The ISP knows who has which prefix, because they handed them out, but the allocation of IPs inside that prefix is handled entirely by the end-user network. The ISP isn't involved in it, so they have no idea which IP is which computer.
With NAT the LAN-side IPs are hidden from the ISP. In v6 the ISP can see the LAN part of the address, but without any way to identify which machine is using which IP that doesn't give them any extra information. All they get is the prefix and a random number. Computers typically change the random number on a regular basis too so you can't even do any long-term analysis on it.
Oh, I see where the misunderstanding is. In cases like the one addressed in Belgium, the ISP actually assigns the same outward-facing IP address to multiple unrelated customers, and NAT is performed on the ISP side. Somebody who has merely recorded the IP address that made a request therefore has no legal way of determining that it came from you or someone close to you, rather than a number of complete strangers who were assigned the same address, unless the ISP maintains a record of what connections were mapped.
As far as I know, in the US this is mostly common for mobile providers. If we are just talking about a NAT in your home LAN, this won't help you for privacy/security: law enforcement and whoever else still know that the IP address is yours.
That would normally be called CGNAT. Yes, that does change things somewhat... except what's actually going to happen is that people will record the port number and the time as well as the IP, and the ISP is going to record every single connection you make in a big database, and then bill you for the privilege of doing it. Law enforcement will still be able to identify you, now your ISP has a record of everything you've done, and you're still dealing with the headaches of NAT all the time. Doesn't really seem worth it to me.
As far as I know, several court cases in Germany have confirmed[1] that the mapping of dynamically assigned IP to customer identity may only be stored for 7 days. I imagine the same upper bound, or an even tighter one, applies to the records you are talking about.
Around here I'd expect something more like a 7 year minimum to be more likely...
Limiting the timeframe does improve the costs and the privacy impact, but the ISP will still need to build and run all of the logging infrastructure, and the end result is that you'll still be identifiable.
- No transition or migration design. It seems like IPv6 was designed as if it was being built instead of building IPv4, and didn't consider how the move would happen beyond something like "everyone run dual-stack IPv4/IPv6, and once that's at 100% we'll turn off IPv4."
This results in a stale-mate of sorts:
As a server operator, as long as you have IPv4-only clients, you need an IPv4 address. There are no [1] IPv6-only clients, so implementing IPv6 at all is a lot of work with no tangible benefits for the next x years [2].
As a client, you can't go IPv6-only without losing access to the IPv4-only services. There are no[1] IPv6-only servers, so implementing IPv6 at all is a bunch of work with no real benefits for the next x years[2]
[1] no meaning a tiny fraction that rounds to 0%
[2] x being the number of years before there's a significant number of IPv6-only servers or users.
To some extent this is unavoidable. Anything that is 'IPv4-like with larger addresses' is very much incompatible with any IPv4 equipment or setup at the edge.
You could design something where the IPv4 could be left unchanged in the core of the Internet. But the core of the Internet has supported IPv6 for a long time, it is the edges where the problems are.
Just something as simple as writing an address to a log file would fail if addresses suddenly became bigger.
> Anything that is 'IPv4-like with larger addresses' is very much incompatible with any IPv4 equipment or setup at the edge.
I disagree somewhat. You could imagine a hierarchical routing structure where IPv4 NAT servers double as IPv4ext routers and gateways. All current servers maintain an IPv4 address which, if the server is unaware of IPv4ext, will not be able to decode things like full client IP address for loging, giving an incentive for server operators to upgrade.
Meanwhile, unaware client end-points connect to IPv4ext servers just as before, via NAT, but of course don't have end to end connectivity to other IPv4ext clients, giving them a (weak) incentive to upgrade.
This would go on for a decade or two just like it did with IPv6, until the moment where virtually all firmware and software is upgraded. At this point carrier grade NATs would stop mangling, the IPv4 only packets are dropped from the core and full non-hierarchical routing can commence on the full IPv4ext address field, finally solving the IPv4 exhaustion problem, in addition to the already solved e2e problem.
I agree this backwards compatible deployment scenario is much more convoluted than a clean slate redesign, and it's hard to imagine it could have seen preferable in the 90s, before wide-spread carrier NAT was a thing.
1) As far as I know, nobody ever wrote down a protocol description, and preferably made an implementation. The devil is in the details. It is very hard to estimate if such a design would actually work.
2) At the moment, the core of the internet and just about all host operating system support IPv6. The hard part is getting the edge networks to upgrade. My guess is that your proposal would run into similar issues.
There are a number of proposals that build on these ideas, for example EnhancedIP. Typically, they would encode the extended addressing info in an options field. They were to late the party and missed the circa 2000-2005 window where it became clear Ipv6 will be an uphill struggle. Back in the day, only naive proposals like ipv7 existed, "ipv4 with larger address" but that solves little.
The fundamental difference compared to dual stack is that there is no technical cost to deploy it outside software updates and very little risk - aside from the dubious security benefits of NAT. Not only the core, but virtually all hardware and software on the Internet today support ipv6, but there is an enormous cost to configure it to work.
This flexibility and drop in upgradability of things like EnhancedIP comes with the significant cost of breaking the internet into 2^32 independent routing domains that prevent you for getting the full benefits of the larger address format. This is an acceptable trade off only in retrospect, after the v6 "failure".
There is a large cost to configure IPv6 because most operators have ignored IPv6, waiting for the IETF to magically get it right.
There is very little consensus within the operator community on how to deploy IPv6. The net effect is that there is an endless series of configuration options.
Which leads to having to select equipment very carefully to make sure you get an overlapping feature set.
The problem with something like encoding extra address bits in IPv4 options is that you would have to get a large group of operators on board for it to get any traction.
For example, the ISP that I use for my home internet connection give customers a static (officially 'stable') IPv4 address. It may not be beneficial for them if a next generation internet protocol would force the deployment of NAT boxes.
The downside of dual stack is that you have to manage 2 networks. The benefit it that you manage two completely separate networks. IPv4 routing has very little effect on IPv6 routing.
Merging the two, as is done for example with NAT64/DNS64, leads to network issues that many people don't understand. I think you would get the same if you mix legacy IPv4 stacks with stacks that encode extra bits in an IPv4 header option.
This is of course completely ignoring the fact that many firewalls just drop anything that has IPv4 options. So deployment may be just as an uphill battle as IPv6.
> The problem with something like encoding extra address bits in IPv4 options is that you would have to get a large group of operators on board for it to get any traction.
Sure that's why you have things like IETF, to coordinate such changes. If that were to happen, the EnhancedIP option would quickly become transparent, as the core of the internet upgrades firmware in a few years. I'm not in any way proposing this to be a good idea today, let alone that it could be deployed in ad-hoc uncoordinated fashion.
> my home internet connection give customers a static (officially 'stable') IPv4 address. It may not be beneficial for them if a next generation internet protocol would force the deployment of NAT boxes.
In that case you become the owner of your own routing domain and you have the option to provide your "customers" with an extended IP address that is e2e reachable from the outside world, while NATing the rest of the legacy devices. Your ISP does not have to do anything aside from not filtering options, that's the beauty of a backwards compatible solution.
> Merging the two, as is done for example with NAT64/DNS64, leads to network issues that many people don't understand.
The complexity and fragility of something like NAT64 comes exactly from the fact that it tries to bridge two separate internets. An EnhancedIP NAT is simply a transparent router for EnhancedIP aware endpoints within the domain it controls. You can freely mix legacy and upgraded devices in your network with guaranteed interoperability and you get e2e connectivity if both end points and any NATs in the route are upgraded. The rest of the network only "sees" IPv4 traffic as far as they are concerned.
This is literally my problem with upgrading to IPv6 currently. And at the cost of potentially embarrassing myself, I haven't really looked into what the potential problems are going to be (and I'm embarrassed to ask :-) ). My ISP will happily switch me from IPv4 to IPv6 but I've got absolutely no idea what the potential problems are. This has put the task into a near perpetual, "I'll look at that when I'm not so busy". I'm sure I'm not alone in this...
sure, we can simply stay on v4 and encapsulate everything into UDP and use vhost or other names and simply treat v4 address + ports as the solution. economically both are costs of growing the internet. (any solution requires a lot of application changes anyhow, v6 is simpler, but requires ISP buy in, so what app devs can do?)
Why is IPv6 more attractive for address exhaustion than IPv4 NAT?
As the article argues, you can't run IPv6-only. You need some strategy to reach IPv4 services on the internet because the internet is IPv4. That answer is going to be either publicly routable IPv4, IPv4-to-IPv4 NAT, or IPv4-to-IPv6 NAT. If you do the latter (or if you do dual stack) you can route directly to other IPv6 hosts without NAT - but what's the benefit? Are there systems of communication between parties on the public internet that can guarantee native IPv6 on both ends, don't want to use IPv4 NAT, and don't want to set up a point-to-point VPN?
(I am actually okay with IPv6 ULAs for private addressing on private VPNs to avoid RFC 1918 collisions/exhaustion, but that also saves you a lot of the complexity of IPv6 deployment because you don't need any network device support, you generally get address assignments from your VPN layer and don't need to think about SLAAC or DHCPv6 or anything, etc. And it's unrelated to public IPv4 exhaustion.)
When I was on an ISP with CGNAT I regularly saturated the connection tracking tables which resulted in all new connections failing until some some slots were freed up.
NAT also makes it difficult to run any kind of server at home (PCP support varies) or use any kind of p2p protocol.
NAT traversal techniques don't work all the time and even when they work they may only help for coordinated connections but not for unsolicited contacts.
I've had the same experience when my ISP put me behind a CGNAT: the port table got reset every other day, and some other customer could have taken the port you wanted at that point, applications with ports hardcoded over number 2000 did not work because they could not be requested, people with PPTP VPNs could not use them anymore as GRE didn't work. Plus, enjoy getting banned from things because you share your IPv4 with plenty of strangers. The solution from the ISP was to give those who complained a "fixed IPv4 plan" for free, since that pulled you out of their IPv6+CGNAT deployment plan, at least for the moment.
> NAT also makes it difficult to run any kind of server at home (PCP support varies) or use any kind of p2p protocol.
I care about this greatly, but I'm not clear that ISP's do. On the contrary, my ISP's TOS states that I'm technically not allowed to run my own server on my home internet plan.
P2P isn't just file sharing and home servers, for example the popular PS4/Xbox/PC game "Destiny" is all serverless P2P instances. I can't imagine an ISP banning you from playing PS4 games.
I recall reading that you could make P2P connections work behind a NAT by having an external server route the connections initially. Is this not true, or does it only work in some circumstances?
> Are there systems of communication between parties on the public internet that can guarantee native IPv6 on both ends, don't want to use IPv4 NAT, and don't want to set up a point-to-point VPN?
WebRTC is one example of something that can greatly benefit from having publicly routable addresses on clients (in practice this tends to mean IPv6). If both clients are behind IPv4 NAT that doesn't allow hole punching, they will need TURN (or media) server in order to communicate. While clients might be close to each other (e.g. same apartment building), that TURN server can have horrible routing for this set of clients. For example, it could be in Europe while both of the clients are in west coast of USA (and that's not even nearly the worst case).
- There are limits to how many devices you can put behind a single IPv4 address. There is the case of Belgium where law enforcement asked ISPs to limit CGNAT to 16 customers per IPv4 address. Obviously for law enforcement, if an address is shared between multiple customers it makes investigations harder.
- A second problem it that you may lose geographical resolution if customers for a wide area share a pool of addresses. For some ad placement you really want to know where addresses are.
- But the bigger problem is that network speeds keep growing. Compared to an IPv6 router, boxes that can do NAT at a large scale and high speed are quite expensive. So an ISP has an incentive to move traffic volume to IPv6. Relatively low volume oddball sites can go over the NAT box.
Do these arguments not apply to IPv6 customers speaking to legacy IPv4 sites? They also have to go through IPv4 NAT, it's just that the NAT is converting it to a public IPv6 address instead of a CGNAT IPv4 one. Wouldn't law enforcement and ad targeting be equally unhappy by piles of IPv6 users being converted to the same IPv4 address?
If enough of the Internet is running IPv6 that you save significantly on performance by bypassing NAT for IPv6 sites only, that seems worthwhile, sure. But also I'd intuitively find that surprising, at least at present - maybe my intuitions are just wrong about how much IPv6 there is.
The most recent figures I've heard were that something like 40-60% of traffic (by bytes) on a dual-stacked client ISP will go over v6. I heard that stat about 4-5 years ago, so it seems reasonable to expect it to be even higher nowadays.
Another advantage is that v6 is easy to hand off early, but if you're CGNATing v4 then your v4 traffic has to go via your CGNAT routers. For cost reasons you probably want as few of those as possible, which means v4 traffic may need to go further to reach them. T-Mobile in the US is like this; v6 traffic is passed off as soon as possible and gets a relatively direct network path, but v4 traffic has to go all the way to one of their datacenters to get NATed. That can add a lot of latency.
> Do you mean ~65k devices behind a single public IPv4 address? [0]
That's an absolute limit of 2^16 (65k) - the practical limit is much lower.
If you only allow one connection per client, then yes, you can get to 65k with TCP/UDP.
If you want more than one connection per client (e.g. because the user wants to download content from Facebook while also downloading a YouTube advert), you need to allocate multiple ports on the NAT device.
I'd imagine that most clients need at least 2^4, and possibly up to 2^8 simultaneous connections to ensure that you don't introduce problems. At the level, you have a limit of 2^8 - 2^12 clients (i.e 256 - 4096).
The 65k limit only applies to concurrent connections to the same remote ip and port. Meaning that you can only make 65k connections from a single IP to the same port of another IP. Which is unlimited for all practical purposes. However, popular services that could potentially see a lot of connections - ban IP addresses, do rate limiting, don't allow that many connections from a single IP. This in turn drives policies of small number of clients per IP, sometimes even rotating IPs, all to minimize effect of bans on users sharing the same IP.
For a typical provider, a large proportion of their traffic is going to go to a limited number of properties (e.g. facebook, google, youtube).
Each of those properties is only going to return a limited number of IP addresses, and all of the traffic is going to be to a very small number of ports (i.e. 443/80). I can well believe that clients connects via a single ISP to a single remote port a large multiple of times.
You can actually get more than 65k connections per address depending on NAT technology. Traffic coming from 1.1.1.1:80 to 9.9.9.9:12121 can be mapped to 192.168.1.1:3333 while traffic coming from 2.2.2.2:80 to 9.9.9.9:12121 can be mapped to 192.168.1.100:9999. GCNAT devices usually support that.
Native IPv6 is cheaper than NAT at ISP scale. If a consumer ISP adopts IPv6, half of their traffic will be native IPv6 without NAT. If the ISP tries to do NAT444 then all of their traffic will be NATed, requiring more equipment.
I never truly delved into low level networking, but I generally got a grasp for IPv4, I can setup simple networks and I think that I understand what's going on on every level. Now despite the fact that I tried to understand IPv6 multiple times, I failed miserably all the time. I tried to setup IPv6-over-IPv4 OpenVPN, it did not work despite all efforts. IPv6 is just too complex. At this point I wish that IPv6 would be just IPv4 with 16-byte address (or better 8-byte, because that's really enough for everyone and another 8 bytes I have no idea who really need that, and our computers work natively with 8 bytes), keeping all concepts the same. Now I'm aggressively against any IPv6 and I'll do only the minimal amount of work to support IPv6 clients for my services while using IPv4 for my own infrastructure everywhere.
IPv6 is in no way more complicated than IPv4, especially if you include all the things you need to make IPv4 work in practice (NAT, techniques for dealing with NAT, etc.). IPv6 is different which is probably why you are having trouble: you wanted something just like IPv4 but with larger addresses, but that is not IPv6. For me the key to understanding IPv6 was to view it as something totally different, and not try to map my understanding of IPv4 onto IPv6.
Now I am aggressively against IPv4, because over and over I see problems resulting from NAT, or collisions in private address ranges on two LANs, or broken path MTU discovery, etc. The only arguments for IPv4 are economic or political; at this point the technical debate is over and IPv6 is a clear winner (the majority of technical problems in IPv6 deployment are related to compatibility with IPv4).
By and large IPv6 is very similar to IPv4, but of course without NAT.
For example, at my home I get a /48 prefix from my ISP over DHCPv6 (over PPPoE). Then I assign /64 prefixes to my subnets. After that, hosts pick up addresses using SLAAC.
Obviously, VPNs are more complex, but that's not the fault of IPv6.
I disagree. You have to consider network effects. Even if IPv6 was completely perfect, switching on your own doesn't do any good. You need to get most of the network to switch to get the benefits.
Given that there is always a cost to switching, people will consider switching when continuing on the old path will become more costly than switching.
More specifically: "completely technologically perfect". Which is the point being made in this thread: the technical aspect is of only partial relevance. If IPv6 fails because of political problems, or "contextual ones" (like “we could make it technologically inferior but more readily backwards compatible; it would make it less awesome but easier for people to migrate”), then that is still "failure of IPv6".
If IPv6 had been perfect, it would be fully backwards compatible, and there would be no market for IPv4 right now.
Just because that isn't possible doesn't mean there isn't a middle ground.
Every major OS, network device maker, service and program supports it. I can't imagine it "will fail" in any way where everyone goes "ok, forget IPv6, let's move on to IPv7 it's the new thing" and the world says "phew, at last!".
> According to market researcher Gartner, over 1.5 billion smartphones were sold last year
That's an IPv4 internet of address-needing devices every couple of years, just in smartphones. World IPv6 day was 8 years ago in 2011, and then Vint Cerf said there were no plans for an IPv7, and 8 years later there still isn't an IPv7 coming from the IETF. https://www.networkworld.com/article/2200118/router/cerf--fu...
IPv6 can't "fail" for the same kind of reasons huge financial companies can't fail - there isn't an alternative.
Sure there is, it's called IPv4. For profit companies will continue to beat that dead horse with things like CGNAT for as long as IPv6 continues to fail. The failure is a process not an end state, IPv6 is falling for two decades now and the eventual complete deployment in the year 2040-2050 will be it's complete and giant failure, unless something else comes along to make it irrelevant.
It is easy enough to criticize the IETF and the wider IPv6 community for the mistakes they made.
But as far as I know, nobody came up with a credible protocol that is fully backward compatible with IPv4.
So, you can ask the IETF to come up with a magically protocol that has longer addresses and is still backward compatible with IPv4. But they are only human. So that kind of magic is not going to happen.
> - Demand for IPv6 is highly asymmetrical. The party that is out of IPv4 addresses needs IPv6. But everyone who has enough IPv4 space has no reason to care.
We might need some way to force them... Google has done a lot of good by changing functionality for SEO + chrome by giving warning or giving PR boost if your site has a certain feature.
They should consider prioritizing sites that have both IPv4 and IPv6 and also warn users in the browser if the site does not have IPv6.
It's a legit warning too:
"Warning! This site may not work on some networks!"
No? My recollection is the original primary objective of IP Next was to prevent the net's flat address space from collapsing into NATed fragments. The need was immediate and pressing. We failed. Now we all live in what was feared - a post-collapse wasteland of centralized systems.
If you had a national ISP in the US who ran IPv6 with end-to-end connectivity without NATs, a killer app would move to it and then drag all the other ISPs onto IPv6.
IPv6 adoption has been on an exponential growth curve for a long time, with an inflection point where it really started taking off around 2013. Google has some very solid stats to back this up https://www.google.com/intl/en/ipv6/statistics.html
There are absolutely motivations and incentives for the advancement of IPv6, the most obvious of which is the exhaustion of IPv4 address space. The Notice the inflection point of IPv6 adoption in 2013 - this occurs in tandem with the real exhaustion of the IPv4 space. As IPv4 address space becomes increasingly expensive the financial incentives will grow stronger - recent block sales have the price approaching $18 PER IP: http://ipv4marketgroup.com/ipv4-pricing/
Cellular providers have particularly incentives to adopt IPv6, given that by just about any account there are more mobile devices in use globally than the entire IPv4 address space. Odds are good that if you’re using a major cellular provider, you’re actually accessing the internet over IPv6 directly. T-Mobile is apparently already in the process of decommissioning IPv4 entirely.
Work on IPv6 began nearly in tandem with work on NAT, which lasted as a stopgap longer than most expected.
Recognizing major risks to a global system and developing a complete solution a few years in advance of necessary adoption with the only miss being the estimate of how long the stopgap solution would remain viable doesn’t sound like a miss to me. The IETF engineers deserve a little more credit.
An exponential works in an unlimited population or for as long as it's effects are negligible compared to total population size. Once you have converted a significant part of the population, the number of possible targets starts to drop exponentially. You will reach for the highest hanging fruits, sysadmins who don't give a crap, nutcases that hate IPv6 for killing their dog, legacy devices that only Bob knew how to manage but we fired Bob back in '98, and so on.
There's every reason to believe reaching a point where IPv6 is widely enough supported to allow you to turn off your IPv4 address, say over 99%, will take the same number of decades as has taken to get to 50%.
You can already see this reverse inflexion in countries that are further along like US and Germany.
> There are absolutely motivations and incentives for the advancement of IPv6, the most obvious of which is the exhaustion of IPv4 address space.
Which is exactly my point: a system could have been decided that only focused on increasing the address space (in as backwards-compatible a way as possible), but instead v6 tried to roll "everything and the kitchen sink" into it, while making the address space transition about as difficult as possible.
The fact that IP v4 addresses are so expensive just highlights the failure of v6. If v6 had been successful, v4 addresses should have a value of $0.
And if you look at the original group that came up with the idea it was 19 academics and one guy from bell labs - and no one with real skin in the game.
In the mid/late 90's even I as a relatively low level person working in networking at BT I could see the problems with IPv6
It seems like a lot of technology transitions go smoothly, while others painfully drag on for a decade (ipv6, Python3). Are there any common root causes for the semi-failures? Has anyone written about why some succeed and some don't?
Look at the deployment of TLS as a success story. Everyone kept on supporting both old and new, watched the percentages, and then dropped the old when the new had enough penetration.
The whole thing is also a bit of a shell game. Nobody wants to invest in it until they feel like they're "behind" if they don't. So you have a big player or two in order to make it feel like that's the way the wind is blowing.
You can do the same thing with v6, the difference is problem space. TLS is about the client and the server upgrading while IP is about every box inbetween as well. If you look at TLS and HTTP version changes when the inbetween infrastructure is involved (even just a single corporate FW, not the whole path) you're held to legacy versions just the same as IP is held to legacy versions.
Eventually some protocol is the bottom of what a group agrees to speak rather than individuals and that protocol has a completely different set of deployment issues than abstraction layers that can be built between end stations at higher levels.
It is not only about intermediate boxes. Just consider how relatively smoothly various parts of WiFi stack was upgraded or how 2G->4G transition happens with mobiles phones.
The biggest problem with IPv6 is that it a different protocol that requires special support on all levels starting from applications and down to managed switches.
The new WiFi installations do not run old protocols. Surely they may support the older versions, but by default the newer protocols are used. Compare that with IPv6 when after 20 years the protocol is still disabled by default on ISP provided routers in Europe.
Usually, devices have an "802.11n+" options nowadays, dropping support for 11b and 11g has some benefits. It's often enabled by default on new devices, especially since most 11b/11g devices don't support WPA2-PSK so couldn't connect anyway
With IPv6, there are mismatched incentives. There are parties that would have to do the investments and another parties would benefit.
For ISPs, it means investments with no benefits. They do it only once their CGNAT is too overloaded or on other sign of running out of IPv4. When they do it, in the simplest and cheapest way possible, which the informed customers see as worse service, so naturally they want to avoid it.
IPv6 would help network application developers, so they could do more or do what they do now with less, but they have no impact on investments ISPs would have to do.
Then there are parties, that have working IPv4 infrastructure, feel no pressure caused by lack of IPv4, and migration would mean just expenses with zero benefits. Exactly like companies that ran login forms over http, up until browsers started to warn users. That was the incentive, that caused them to switch to https.
I would posit that BluRay has been less successful for two other reasons:
1. DVD video quality is good enough for most.
2. The Combination of DRM, unskippable portions, and similar is enough of a barrier to discourage the upgrade. Personally, I will only watch a movie on disk when I don’t have time to rip it and remove that crap.
That hasn't been my experience. I was watching some instructional DVDs—well-produced, modern stuff https://www.youtube.com/watch?v=v68ZP8tHhnc —on a desktop monitor lately and the difference really leaped out at me, despite my already knowing consciously that the video wouldn't be HD, and the fact that I'm far from being any connoisseur of video quality. Given that standard DVD resolution is never higher than 720 × 576 pixels it really shouldn't have been surprising.
The DRM and unskippable portions were the same for DVDs when they launched and yet they were a bigger success in an equal timeframe. I do not think that most consumers care enough about these two points to actually influence their decisionmaking.
I'd be more interested in how the HD DVD as a very visible competitor blocked BluRay adoption because of consumers wanting to wait for a winner in that war.
Tls was a software upgrade for nearly everything. In fact just by building newer devices that software was just there and ready. Ipv6 is not just a software upgrade.
> So you have a big player or two in order to make it feel like that's the way the wind is blowing.
This assumes markets with little to no competition. But most ISPs are in competitive markets with no trend setting big players and they can't waste money investing into IPv6 or anything else that has no demand if they want to keep the business alive and healthy.
I wanted to buy native IPv6 access from my ISPs for a long time but it was not possible every where. I get it now from a Comcast business account. My Google search traffic is now over IPv6. Admittedly my networking interests are probably too rare to make a market force thru numbers.
That's not true. TLS didn't happen until Google said they will penalize non-https sites. Letsencrypt helped alot, but the momentum was there even before them.
From the client perspective there is the same level of compatibility between IPv4 and IPv6: client can connect to both types of addresses.
> Are there any common root causes for the semi-failures?
Sure is: it weren't broke and they fixed it!
I mean, even today if you take a median python user (a devops person in a big shop, maybe) and ask them to name four major advantages that Python 3 has over Python 2... I doubt they could get past one. It's not that it isn't a better language, but for 90% of its user base who don't do library design it's almost indistinguishable. And it's incompatible!
IPv6 was similar for most of its life. IPv4 wasn't broke.
Now... it's getting toward broke. And in fact lots and lots of client ISPs (mostly mobile ones) are moving rapidly to IPv6, where their systems hit IPv6 backends of all the big content providers.
I honestly don't know that I agree with the thesis of this article. Network operators who want to deploy IPv6 in the modern world certainly can, and are. That's pretty much the definition of a smooth transition, even if its taking a few decades longer than expected.
But is either Python3 or IPv6 really a failure? Sure the migration has been slow, but has still been rolling on pretty consistently forwards. There are no major reversal in the trends of either IPv6 or Py3k adoptation, and especially for IPv6 there is pretty much no alternative out there.
Maybe just a decade is not all that long period and the tech community is too impatient due the historically rapid pace of changes.
Let's see... Can I get a /10 IPv4 block for my company without paying a small fortune? Can I do the job using IPv6 only? Does the vast majority of mobile and emerging market customers have end to end connectivity?
If the answers are "No", "No" and "No", I would have to say that indeed, IPv6 really is a failure, after two decades and monstrous investment thrown at it, it has failed to solve any of the practical issues it was supposed to.
It's a gigantic failure, both in a costs vs. benefits approach, but exponentially so when considering the opportunity costs of being still stuck with IPv4.
Take a look at COBOL in our daily lives. The switching cost is horrible and lets face facts, developers don't seem to want to develop the next cool version of COBOL. I sometimes wonder about switching costs when you have two or more groups that have different beliefs, practices, and views of the daily grind.
Infrastructure & Software costs money and time to switch with no real personal benefit and requires a change in knowledge. Both your examples require a hard switch and don't have a nice easy transition plan. Add taking away things that are familiar to the people in the field and you have a bad, long transition.
What do you mean "incompatible"? You can run both of them at the same time, they work on the same links, in the same OS stacks, with the same programs, and you can talk between them or tunnel over them with a variety of transition mechanisms (dual stack, Teredo, 6to4, 6rd, 6over4, ISATAP, 6in4/4in6, NAT64/DNS64, 464xlat, DS-lite, MAP-T/E, 4rd, LW4over6, ...).
They're about as compatible as they can possibly be, given the design of v4.
I mean that IPv6, to my (admittedly poor) understanding, does not contain a specification as to how to route "legacy" IPv4 packets. To have IPv4 packets work in an IPv6 network, you need a whole IPv4 infrastucture. And when you are there, you may as well just use IPv4.
But maybe I am mistaken. Does the IPv6 specification proposes way to map an IPv4 network inside an IPv6 one? Or are all these later hacks?
I'm not fully sure what you're asking for here exactly... you're going to need a v4 infrastructure to route v4 packets, because that's what having a v4 infrastructure means.
You can map the entire v4 space into a v6 /96 with NAT64. That works fine, giving the same sort of outbound-only connectivity that NAT gives in v4. Does that do the job?
This can be deployed quite quickly if mandated as a requirement for any ISP to operate (ISPs usually need some license from local municipalities or something of the sort). They'll implement it in an instant. Otherwise, they'll just sit doing nothing, and it remains a chicken and egg problem.
That is clearly false. Building codes, workplace safety codes, zoning rules, noise ordinances, even aesthetic ordinances exist in most non-rural places.
Loose coupling and no second system effect. IPv6 should have been extended address space and extended address space only, in a manner backwards-compatible with IPv4. You think ARP is broken? Great, implement a fixed version of ARP for both IPv4 and IPv6, meanwhile we'll spec IPv6 to use ARP. Don't design IPv6 to use your new thing called NDP that layers completely differently. You think everyone using NAT is wrong? Great, go convince them. Don't tell those people "I don't care what you think, I'm right, and you better agree with me in order to deploy the new thing." They're going to - entirely justifiably - not deploy your new thing.
The thing about NAT that for network operators it is a negative externality. For them it often simplifies their job. They do not feel the searing pain it inflicts on network application developers. It's hard to come up with a carrot to convince operators that NAT is wrong because from their perspective it isn't, even if it harms the internet as a whole.
As a network application developer I haven't felt much pain from NAT - I need to run a central server to relay connections, but that's about it. And oftentimes I need to run a central server anyway for discovery or authentication. (A few years ago I worked at a startup that enabled secure remote access to corporate networks, as in you could connect from a roaming laptop or mobile app into the network, browse the web, access network file shares, etc. We had a straightforward and uncomplicated proxy server with access control that we asked people to install and forward a port on their NAT for; it worked fine. We prototyped a relay server that customers could run in AWS, where our proxy server would connect outbound. I don't think any customers absolutely needed it. And we definitely preferred having one of our servers involved somehow as an intermediary so that customers weren't exposing Windows file shares to the public internet and hoping Windows authentication was enough....)
You're right some some applications are more effected than others. It sounds like you were dealing with business customers, "asked people to...forward a port on their NAT" is not a viable strategy when dealing with consumers.
I work on P2P applications, so NAT is the bane of my existence.
>we asked people to install and forward a port on their NAT for
At this point I no longer believe you. Having worked in the ISP industry for quite some time, only a very small portion of the more technically advanced users can do this successfully. Most users dont remember their passwords to even get in their device.
Just because windows firewall security is balls doesn't justify writing a nat helper or proxy for every protocol their is. You have just accepted the abuse that nat doles out as a norm.
Increasingly, even those who know how to do it are unable to do so, because they are behind CGNAT and the PCP doesn't work or is not implemented at all.
NAT is only painful for applications that implement arbitrary inbound connections, such as peer-to-peer connections, and applications that use separate control/data connections. The former is understandable because it's necessary, the latter is arguably lazy application developers.
Peer-to-peer is largely solved with UPnP port forwarding, but most of these apps can also at least be configured to use a specific port range, education can then be configured on the router to forward.
Then the are the badly designed protocols. That's perhaps a bit harsh, they have their reasons, but using multiple ports is a bit lazy vs using encapsulated packets (eg where you can send either a control or data packet over a single connection, or even send multiple data streams concurrently, in both directions).
FTP is one example, where a separate port is used for data transfers. This is "simple" from the perspective that the data port just contains the raw file contents, no extra encoding, but very painful from a network point of view. I used to support web hosting customers around 2000, when ftp was commonly used for maintaining site content, and people didn't understand when to use PASV mode, server operators didn't always setup the firewall to allow inbound data ports, and occasionally you'd run into the worst case of both client and server behind NAT.
SIP is another example. It uses multiple streams, but is built assuming everything has a public IP. The message it uses to setup this stream includes the system's IP address, which is the private non-routable IP when behind NAT.
Contrast these to a multiplexing protocol like HTTP/2, where it's basically transparent to network operators (still just a single TCP connection on 80 or 443). There's many other examples of multiplex use in more proprietary systems: online gaming, for example, sends different packet types over a single connection -- it doesn't require a separate "movement" and "shoot" port for each connected player. Most sites/apps using web sockets also work like this, with each piece of data encapsulated inside a message wrapper (usually JSON).
I'm being a bit unfair, because FTP predates NAT, and SIP was being created around the same time -- though I'd argue SIP's assumptions about the network environment (and seeming compete ignorance of NAT) were both poor and unnecessary.
> Peer-to-peer is largely solved with UPnP port forwarding, but most of these apps can also at least be configured to use a specific port range, education can then be configured on the router to forward.
Until Comcast helpfully replaces the cable modem in a working setup with a router/WiFi/hotspot abomination, so the network ends up double-NATted, and anything that tries to punch through UPnP- or TURN-style stops working.
And then puts you behind CGNAT after they run so low on addresses that they don't even have enough for one per customer, giving you triple NAT with one of the NATs being completely out of your control. Good luck getting anything through that.
Think about FTP. Client is behind NAT, so needs to use PASV mode (server opens arbitrary data port for client to connect to, instead of server connecting to arbitrary data port on client).
If the server has a firewall that blocks all inbound but 21/tcp, or is behind NAT with just 21/tcp forwarded, no data transfers are possible.
These are totally different setups from a network operations point of view, but look identical from application and user point of view.
I think this is what the parent was getting at: both setups effectivity prevent a user from accepting arbitrary inbound connections to their machine.
If a firewall isn't doing ingress blocking then it doesn't really serve much of a purpose now does it?
Ingress blocking being a side effect of NAT is the whole point of equating it to a firewall. It's roughly similar for all intents and purposes except that it also provides socket translation, and socket translation is really useful so every firewall worth mentioning also provides NAT.
That ipv6 initially did not address the usecases for socket translation outside of multiplexing addresses is probably one of the reasons it hasn't gained much ground in the decades it has been around.
Anyway, the point is that most of the headache that NAT causes application developers is also true of firewalls that block inbound connections by default. Removing NAT from the equation doesn't save you.
It’s late to the party but it is a shame you are getting down votes. Firewalls will still be all sealed up to where inbound connections are strictly limited. You’ll still need something like upnp to request a hole punched through the firewall.
No, I think that argument makes perfect sense. A stateful firewall doesn't depend on NAT but you get all the downsides of NAT from a working stateful firewall in default-deny mode: you still have to talk the firewall into allowing the relevant traffic through, and without that you still have connections that work in one direction and not the other. The only thing that's different is address discovery, but you can solve that by just asking the firewall what public address to use at the same time that you ask it to open the port. (Or curl whatismyip.akamai.com or something.)
So if NAT is a problem for your application, so are the stateful firewalls implicitly envisioned by those who advocate for assigning unNATted public addresses to devices on home networks.
As someone who works on P2P applications, if all I had to do was use PCP to open a pinhole in a firewall it would still be a big improvement over dealing with NAT.
For one thing lack of NAT makes it much easier to deal with multi-homed systems. For various reasons, multi-home is much more common with IPv6 than IPv4. Without NAT I can discover thing like what an address's scope is without querying the network. Having to ask a remote server to discover a global address turns what should be an atomic operation into a potentially troublesome state machine.
NAT also create annoying corner cases when there are local peers reachable via an address which also has a NATed global address. You may not be able to tell that the peer's address is not globally reachable, which is a problem if you want to advertise that peer to others.
> For one thing lack of NAT makes it much easier to deal with multi-homed systems.
It’s the opposite imo. Lack of NAT makes it impossible to do policy based routing enforced at a router level, eg route VoIP over ISP 1, and Web over ISP 2. Without NAT, each IPv6 PC is issued one or more IP addresses per WAN, but has no idea when it’s appropriate to use one over the other. (SLAAC router advertisements aren’t sophisticated enough)
This is the sort of thing I was talking about when I mentioned negative externalities elsewhere in this thread. NAT is nice if you want to do things like that, but those sorts of tricks create big problems for people like me. Being behind NAT with multiple external IPs and an unknown policy for which gets used when is a nightmare scenario for P2P applications.
Exactly! They say NAT is wrong, they want every device to be publicly routable and accessible from the whole internet. Nobody sane would allow that. One stateful firewall in between and you have the same problems as with NAT.
You hit on the problem with IPv6 designers- they took a solution (bigger address space) to a problem (not enough addresses) and they added a bunch of other changes (No NAT, No DHCP, ARP vs NDP, weird address scheme, etc) that arguably made things worse.
Then they wonder why people aren’t adopting it.
(Its the same complaint I have against Let’s Encrypt. They shoved down a policy which is antithetical to helping their mission.)
I think this is what will cause USB-C to fail. It’s taking a simple problem (allow reversible, higher-bandwidth connections) and making it complex.
The latest spec requires encryption. In a cable. Which might be ok for some applications, but certainly not necessary for all items. Now you have so many versions, which may or may not implement a laundry list of features. And people just want simple, no fuss cables.
> I think this is what will cause USB-C to fail. It’s taking a simple problem (allow reversible, higher-bandwidth connections) and making it complex.
Actually, it's still simple. For devices and hosts using USB 2.0, the only real change with the USB-C connector is a single extra resistor. For devices and hosts using USB 3.x, they only have to detect which of two pins has the resistor on the other side to select which of the two high-bandwidth channels should be used. And there are two main types of cable: USB 2.0 cables and full-featured cables, like the old non-USB-C USB 2.0 and USB 3.x cables.
The extra complexity only appears when you want the extra features which are new to USB-C: higher voltage and/or current, alternate modes, using both high-bandwidth channels at the same time (USB 3.2), and so on.
I assume they're referring to the 3-month certificate lifetimes, which all but force you to automate certificate renewal, whereas the 1+-year certificates of the past let you treat it as manual sysadmin work. This was based on a belief that automating certificate renewals is the right thing to do.
Still, LE seems to be wildly more successful than IPv6. I suspect in part that's because they were more technically right - or at least it's more feasible to add the automation than to rearchitect an IPv4 network - and in part because you can do manual certificate updates. (For complicated and entirely uninteresting reasons, I do manual certificate updates on my personal website every three months using certbot certonly --manual and scp, and it works.)
I'm also way more personally sympathetic to LE because they're pushing the change for security reasons (revocation doesn't work, so we need to move to very short-lived certs) and not mere elegance ones. Rolling out IPv6 as designed brings no security benefits either to the user or to the ecosystem, and carries quite a few potential security risks.
It's worth pointing out, in terms of LE being "wildly more successful", that this represents a single organisation, with a security critical role on the web, approaching a monopoly. That's actually a worse situation than if 100% of hosts on the internet supported (different but compatible implementations of) IPv6.
Here is a chart showing the trend for LE marketshare (under the IdenTrust root):
I really support LE's mission, and celebrate their success, but would feel more comfortable if a separate organisation tried replicating what they had done, running the same service but with distinct personnel and assets.
For reference, here is another chart showing the run down of the remaining IPv4 supply:
I think another big thing with Let's Encrypt is that they are free while their legacy competitors cost money, which is on the brutal end of incentives.
No NAT/DHCP is an implementation choice not a protocol limitation. NDP is the only real "you must do <x>" in your list that is true. The address schemes are either straight from v4 (link local, private, loopback, public, multicast), optional (temp address), or just best practices (/64s)
Your ability to implement this as a network operator is also constrained by what your network devices and client devices support. Since there exist devices that don't support DHCPv6 and only support SLAAC, /64s turn from a best practice to a requirement. Since everyone made fun of NAT, NAT66 implementations did not exist until very recently and they're still uncommon, even though it's been technically obvious what to do since day one.
You can implement IPv6 by ditching all your network hardware, installing commodity Linux boxes, writing some patches to iptables, and insisting that nobody bring Android devices onto your network unless they run your in-house fork of AOSP. I just think most people would not consider that an option in scope.
A successful solution would have pissed a lot of people off. Every faction that had just one little enhancement, that could by itself probably have been okay, would have to have been told no. That's a hard thing to do.
Sometimes you have to say "yes" to one powerful faction, regardless of whether their request is technically a great idea, in order to get enough political capital to fend off everyone else.
> Don't tell those people "I don't care what you think, I'm right, and you better agree with me in order to deploy the new thing." They're going to - entirely justifiably - not deploy your new thing.
Pay attention developers. This attitude is all too common in our industry.
The other thing that V6 does that it should never have done is the extension header nonsense. That makes it possible to layer protocol inside protocol essentially forever. Hardware designers just love this feature. In practice, a lot of hardware vendors do not support it and just punt to exception cases when they hit an extension header. I'm a little surprised that that there isn't some widespread DOS that involves extension header handling botches.
I have been getting native IPv6 from my ISP for nearly six years now. It is not quite as cool as it could be, because I get assigned a new prefix every 24 hours, but still, IPv6 is there, and it "just works".
When I connect to machines on my home network in any way involving avahi/zeroconf, the machines talk to each other via IPv6 by default.
At work, it's a different story. I have drifted from a sysadmin/helpdesk role into a programmer position, so that is no longer my concern. When it was, however, there was little incentive to use IPv6 - everything worked and continues to work just fine with IPv4, and sometimes there were even some rather esoteric problems with Windows' "Network Location Awareness" when IPv6 was enabled.
>I have been getting native IPv6 from my ISP for nearly six years now.
Meanwhile Danish ISPs refuse to implement IPv6 because: There's no demand.
That completely missing the point and their responsibility in my opinion. There's never going to be any significant IPv6 demand from private users. At work however we have customers that have started to request IPv6 only devices and networks, because there's no need for IPv4 specifically, and in some ways IPv6 is just easier (for example there's no need to do NAT).
For IPv6 to be successful the ISPs need to role it out, regardless of demand. The issue isn't necessarily at the consumer end, but the ISPs are part of the Internet and they need to help develop it, regardless of profitability in the next fiscal year.
Elsewhere, the ISPs are doing the IPv6 rollout in the worst possible way imaginable: DS-Lite with no PCP for AFTR (i.e. no way to have incoming IPv4), and allocating only /64 subnet, where their CPE is mandatory in router mode, no way to switch it to bridge mode (thus losing control of your own gateway. I'm talking about you, UPC/Liberty Global).
For just consuming the web, it is fine. For switching from public IPv4, is is insufficient.
NAT traversal (hole punching) works for CGN well, doesn't it? sure you need a coordinator/RP between to CGNed users, but that is not really an issue as far as I know.
Hole punching works for applications that are designed for it, and can invoke the coordinator. Sometimes, you just want plain old incoming connection (in my case, VPN).
BTH, I've never tested whether it works with CGNAT or not. It would be additional hop to jump if I would give up my IPv4 address, which obviously I'm not going to.
End user residential connections usually need a DynDNS as there's no guarantee you'll get the same IP for any foreseeable time period. So dynDNS could be bundled with hole punching. (It just allocates a port on the CGNAT, due to cost concerns I'm guessing these are rather dumb TCP/UDP devices, so almost anything will work through them.)
Of course it's a lot messier than getting a static private address allocated.
This will not help you if you have something like an IP camera that you want to access from outside your home, since the address will change frequently.
The only good thing about UPC/Liberty global's implementation of DS lite (now "Ziggo" where I live) is that they will switch it back to IPv4 with a single phone call to the help desk. I can live without IPv6, I cannot live without being able to reach my home server and IoT things.
I don't think the success of IPv6 as a whole hinges on these residential ISPs. I think there is enough momentum for IPv6 already (mobile users especially) that we get a healthy coexistence of IPv4 and IPv6, where new stuff gets designed for an IPv6 fastpath and limited support for IPv4 legacy shims for the "long tail" of adoption.
I guess the ISP space isn't competitive enough that they will ever go "looks like our ipv4 users get shitty latency and more congestion on facebook than the competitor's ipv6 users, so we're gonna upgrade next year!", but their IPv4 setups will probably eventually succumb to attrition too and be replaced by IPv6 gear.
>> Meanwhile Danish ISPs refuse to implement IPv6 because: There's no demand. That completely missing the point and their responsibility in my opinion.
Responsibility to whom?
If there's no significant demand from end-users for something, then we're relying on there being a benefit for access providers.
>> For IPv6 to be successful the ISPs need to role it out, regardless of demand.
>> regardless of profitability
Can anyone give examples of a successful technology roll-out where there was no demand, and no profit to be made?
What you're observing might be your operating system's behavior. There is a privacy feature of IPv6 called "privacy addresses" (or sometimes "temporary addresses").
Some (most?) operating systems rotate the v6 privacy address daily or more often. The benefit of this is a) address not transparently based on permanent ethernet hardware MAC address and b) changes over time. Both are meant to hamper tracking.
If you're on a Mac and using IPv6, you can see these temporary privacy addresses stacking up over time if you type `ifconfig en0`. Old ones don't disappear immediately when rotated out since you need to be able to receive packets for a while. They are marked "deprecated" for some time before they disappear.
> because I get assigned a new prefix every 24 hours
Which kinda defeats the purpose of having a globally reachable unique address in a lot of respects. How am I supposed to allow connections to this device in my firewall if the address is always changing?
There's advantages and disadvantages to this approach. When we're talking about residential networks, some consumers won't care about the inability to do that, some will. Those that do care also have to weigh the privacy concerns about the fact that they have a now static prefix for their networks, much like static IPv4 addresses.
Personally I'd prefer ISPs to take an approach like this by default, but allow the option for the consumer to have a statically assigned IPv6 prefix for free if they want it, who understand its implications.
> When we're talking about residential networks, some consumers won't care about the inability to do that, some will.
This prevents also to create products that need a public address. I think it is a real brake on innovation, who knows what could be invented if everyone had a public ip address ?
[devils advocate] ISPs are businesses, they are also there to make money, those customers who want a static address may have to pay extra to get one. They know static IPs are more valuable so they won’t give them out by default, ipv4 was the same.
>> There is more than enough address space to give a person a static IPv6 network.
>> Comcast is guilty of this. Verizon doesn’t even offer IPv6 on FIOS.
Why would ISPs not deliberately(!) change address(es) for cheap/residential plans, to provide a reason for those customers to care about this to pay more for a pro/business plan with a static IP allocation?
Most operating systems these days support IPv6 privacy extensions where a device will pick a semi-random address every 24 hours. IIRC, it is the default on macOS. You can have a static prefix and random addresses per device.
These are some interesting insights into the economic incentives on the deployment side. I'm looking forward to reading the report.
It is also interesting to consider the incentives (or lack thereof) for IPv6 peering. The fact that HE and Cogent haven't resolved their peering dispute from 2009 suggests to me that there is insufficient incentive (particularly from their customers) to do so, even when there are obvious practical effects. (I can't reach openstreetmap.org via an HE IPv6 tunnel even now.)
Perhaps the technical effectiveness of Happy Eyeballs and other backwards-compatibility mechanisms necessarily reduces incentives for improving IPv6?
Huh! I looked closer at the graph and wondered why the line was so fat. If you zoom in, a clear trend appears: far higher IPv6 usage on weekends. About 25% more people using IPv6 on weekends than weekdays. (IPv6 is 21% of the total on weekdays vs 26% on weekends.) I'm surprised there's such a big gulf.
A lot of home users have had IPv6 “silently” enabled, while many corporate networks have never implemented it, or only implemented it for a small portion of services that need it.
I'm curious on how the non-contiguous ipv6 [1] usage will eventually affect the use of the TCAM in vendor hardware. It seems that most TCAM being developed today will never be able to store anywhere near the unfathomably large amount of possible address prefixes being carved - and of course the prefixes are only are going to get more and more fragmented.
Right now the typically default behavior for switches/routers that encounter the exhaustion is to summarize prefixes with a shortened prefix and (possibly) punt the evaluation to the general purpose CPU (example here[1]) - which suffice it to say, introduces a host of security concerns. This means, as a security engineer, in situations where complex/large ACLs exist, I need to be aware of and control how IPv6 TCAM exhaustion failure modes work and plan that eventually my hardware TCAM may be exhausted and fail in a spectacularly bad way.
Or, I just ignore IPv6 almost entirely and just don't have the problem (cleverheadtap.jpg)
What we really need is a killer app that requires end-to-end connectivity. Users have little reason to care about IPv6 right now because the existing ecosystem of services has evolved around the constraints of NAT. As IPv6 deployment expands hopefully we will reach a point where some great new application becomes economically viable.
My biggest fear is such an application not emerging quickly enough. Without an imperative from users for end-to-end connectivity there's a risk that IPv6 networks which somehow break it become entrenched. If that happens we are back to the old chicken-and-egg situation: Users don't care because there's no app and there's no app because the network is broken and operators don't care.
My ISP (Verizon FiOS in NYC) does not offer IPv6 support at all. Users have asked for years. They've promised it for years. It's still not there. So it's not a matter of users asking. Re switching, I think I have one or maybe two alternatives; I'm not sure if they support IPv6 either, and they have their downsides too.
Any potential killer app is going to have to decide whether they want to lose such users, because I cannot imagine an app that is so compelling that I'd switch ISPs for it. And I'm a person who actually wants IPv6 for its own sake. I certainly cannot imagine, say, my parents switching ISPs over an app (and I'm not sure how much choice they have either).
And if such an app arises, it's going to be easy enough for users to use VPNs - it's already common for people to use VPNs to get to region-locked content or (at least as of a few years ago) play LAN videogames over the internet.
Some users have asked their ISP for IPv6, but they are in the extreme minority. The average user is obviously never going to ask for IPv6 because they don't know what it is. Really the hope is that users would complain killer app x doesn't work with their ISP, and eventually there would be enough pressure to motivate the ISP to deploy IPv6.
How would the app become a killer app in the first place if a huge fraction of users can't use it?
And my estimate is it probably takes years to roll out IPv6 on a network that isn't ready for it - how would the app remain a killer app until then and not be disrupted by someone willing to run a proxy server?
There are great apps "requiring" end-to-end connectivity. Cryptocurrency clients, various videochat solutions, many multiplayer games, bittorrent clients, etc. They either force you to set up port forwarding (unless they can do it themselves using UPnP), or they use STUN/ICE or any of the other NAT traversal techniques. As a last resort it's often sufficient if enough of your users are reachable from the outside and the rest can connect to them.
Where it would be really great is mobile. It would make voice and video apps so much better if users who trust each other could directly connect without the latency adding rendezvous host. It would also need some sort of authenticated uPnP like protocol for telling the carrier when to allow traffic through their firewall though. I wouldn’t want random hosts to be able to waste my precious battery and bandwidth by sending unwanted traffic for my phone to process and discard.
Consumer IOT devices really should be peer to peer so it just works without the manufacturer having to deal with security issues on the server side. And because there are two types of IOT providers, those that don't want your data nor the security headaches that entails;those whose business model is about spying on people.
If your IOT device doesn't connect to the internet, then there isn't an issue to begin with (peer to peer on IPV4 works great within your own WIFI, and other non-IP protocols on a different frequency are usually a better choice anyways).
If it does connect to the internet, I would rather have the device phone to one server only, and that server handling public access. It's much easier to keep one server secure than millions of devices that are in the hands of customers.
Of course my prefered option are IOT devices talking to one hub I control in my network, and me deciding how I want to expose that hub. But in that case, peer-to-peer communication is a non-issue just like in the first case.
Most Users of automobiles generally know what a piston or radiator is and how it functions. Even my 74yo mum knows that brake pads squeeze the brake drum and need regular replacement.
> What we really need is a killer app that requires end-to-end connectivity.
That seems unlikely to emerge. Anything you can do with end-to-end connectivity you can do with a server in the middle forwarding packets. Servers are cheap and reliable, so there's very little incentive to get rid of them.
Servers for things like this are expensive and a reason why "the internet" is one of the biggest users of electrical energy. Doing things with extra servers involved in the process always results in an environmental footprint that could be avoided.
I still like the idea of a peer to peer web, with something like hosting in your own browser. This could be a great alternative fallback network with distributed DNS. Most phones are capable. Energy, speed and security are concerns, but in cracking them you'd probably make the web a better place.
I like that idea too. A lot of geeks like that idea. But ordinary people couldn't care less. All they care about is that their latest instagram photo gets a lot of likes. They neither know nor care what goes on under the hood. Unfortunately, that ignorance and apathy is what drives the market.
The problem is that if you want to host something usually you want it to be up and reachable 0-24. And that has costs, and p2p can help with that, but the freeloader problem is not trivial. (You need reputation or some other kind of accounting, that requires solving sybil attacks, and possibly global sync/enumeration, both are hard, etc.)
What if we started charging a small but slowly increasing annual fee for each IPv4 address? And with the proceeds ICANN starts buying back IPv4 blocks and permanently retiring them.
This article is largely about IPv6 in internal networks, not IPv6 in the internet as a whole - as they say, "No one uses IPv6 only. All public network operators, and nearly all private ones, must offer full compatibility with all other network operators and as many end points and applications as possible." Their three choices are about remaining on IPv4 only, running dual-stack IPv4 and IPv6, and using a translation layer to run IPv6-only internally and convert to IPv4 at the border. All of them involve public IPv4 addressing, and the assumption is that the internet will forever be IPv4.
So this means two things. The first is that the desire to move to IPv6 on the part of the article's authors has nothing to do with public IPv4 address space exhaustion, it's based on other alleged inherent benefits of IPv6. The second is that IPv4 NAT already solves the exhaustion problem - you're either doing NAT to IPv4 or NAT to IPv6 (using your favorite 6preposition4 encoding/tunneling scheme), but as far as the public internet is concerned, it looks like you're doing plain old IPv4 NAT.
That might actually have the opposite effect of what is desired. Whoever is charging and benefiting from the fee would then have an incentive to maintain the status quo of IPv4 and continue collecting the fees. We’re already seeing this now as people are selling IPv4 addresses. Scarcity + demand creates market opportunities.
Couldn't they can mandate, that no customer must be charged MORE than the global fee, and violations instantly lose their ipv4 addresses (or rather replaced with v6)?
I don't know who the ultimate benefactor would be - would it be ICANN?
This article completely fails to mention that IPv6 is not just an extension of the address space but a whole different worldview about how to run a network:
- IPv6-to-IPv6 NAT has only been accepted very recently and very begrudgingly. Whatever your views are on NAT, the fact is that lots of people have network designs that rely on it, and if you want them to stop, you're now asking them to couple two major transitions, which is a significant economic cost. (Option 3 in this article is IPv6-to-IPv4 NAT, assuming that the public internet will indefinitely be IPv4; it's noteworthy that none of their options ever envision the public internet becoming IPv6.)
- IPv6 recommends the use of its own scheme, SLAAC, for address assignment, with DHCPv6 being also very recent and poorly implemented - for instance, Android has no DHCPv6 support and plans to never implement it https://code.google.com/p/android/issues/detail?id=32621 . There's also a "stateless DHCPv6" for communicating DNS servers but using SLAAC for addressing; without it, SLAAC expects you to use a scheme called RDNSS to communicate your DNS servers, which is also not 100% supported. So you now need to spend engineering time supporting all of these options because some devices only support one and some only support the other, and you need to come up with network designs that work with both SLAAC (which has strong opinions on how you use /64s) and DHCPv6 (which doesn't).
- IPv6 doesn't use ARP, on the grounds that it's a layering violation, a separate layer-3 protocol that runs directly on top of Ethernet but talks about IP addresses. Instead, IPv6 has a clever scheme for using multicast to transfer the information that ARP would convey, by having machines join multicast groups based on their MAC address. This works very, very poorly with networks that aren't designed to support significant multicast load - for instance an attempted deployment of IPv6 caused packet storms in the MIT Computer Science and AI Lab's network for about a week because their switches were falling back from multicast to broadcast: https://blog.bimajority.org/2014/09/05/the-network-nightmare... So a working IPv6 deployment involves upgrading all of your hardware to hardware that has good support for multicast, which is also a significant economic cost.
- Various protocols like Teredo and ISATAP attempt to set up tunneled IPv6 routing in preference to IPv4 routing, making it hard to do a staged deployment, especially if you have BYOD on your network. For bonus points, because they're tunneled, you get different and possibly worse routes over IPv6, making debugging harder. So that's a cost in additional L1 and L2 support.
If someone had come up with an IPv7 that's just "We extended IPv4 to 128-bit addresses and we left ARP and DHCP and NAT and everything alone," people would have switched to it already. But the powers that be are drowning in the second-system effect and nobody wants all the features they added.
> an attempted deployment of IPv6 caused packet storms in the MIT Computer Science and AI Lab's network
They were relying on Spanning Tree in a who knows how big broadcast domain. Firstly, that's just begging for things to hit the fan. A single device having a meltdown will cause exactly this, a broadcast storm that is able to take down the entire campus, because it was a single broadcast domain.
Secondly, it is a security nightmare. No amount of links or switch capacity will suffice in a single broadcast domain campus, relying on STP, if port isolation and proxy-arp is enabled, along with DHCP snooping, arp inspection etc. So, port isolation is not turned on. Isolation also creates a requirement for a pyramid-shaped network so nobody wants to do that anyway. But back on point, MITM-heaven, anyone can do what ever they want because the L2-infrastructure is not limiting anything. Ethernet does not care about security and Internet Protocol only implements or allows to implement security in gateways that interconnect subnets that reside on separate broadcast domains.
Routing is the answer and this is why I route on the access-layer, as well as on aggregation and core -layers. Route loops are very rare with OSPF and broadcast storms are limited to single switches if you route at access-layer. Also the posible issues with untested code-paths are minimized this way, since none of the switches are seeing more than the equal amount of hosts as it has ports.
I do not agree with SLAAC because I do not believe in broadcast domains the size of a /64 so I'd deploy DHCPv6 in every possible braodcast domain that does not have Android devices in them. Luckily there is no place for Android in wired networks and especially datacenters, so I can happily deploy DHCPv6 in those. And if I ever need to service Android-devices, I can dualstack and let the devices know of DNS-service with DHCPv4! Take that, Lorenzo! Hah! Outsmarted you there!
I mean, sure, CSAIL might have been wrong. (Worth mentioning this is just a single building, not all of MIT.) But if even the MIT computer science network isn't set up "right," there's doubtless a huge amount of technical debt for everyone else who's not an MIT nerd to clean up before they can make IPv6 work. And IPv6 would have been more successful if the designers had taken that into account.
The switches being good at ARP and bad at an alternative isn't down to technical merits, it's down to which one existed first.
And it sounds like turning the intelligent feature off and treating the packets as pure broadcast, just like ARP packets, would have fixed the problem. If the switch can't do that in the right way, it's not the protocol's fault.
Yup, turning off snooping would have fixed the issue at hand but not the poor choice of relying on STP for redundancy.
I've seen this happen a few times in my life in production systems, designed by someone else. Overload a switch somehow and it goes straight in ludacris mode because of the topology. Properly configured networks suffer minor outages only in case of single device meltdowns.
It seems like it took multiple switches melting down from bad software design to cause the problems. I originally had a line about the risk of large broadcast domains but the comments on the post claim they were actually pretty small.
Large L2-networks never work well, they all have some issues. Their existence is purely based on lazyness or believing that Ethernet works like the water main... I admit that I might be more obsessive compulsive than most but I find reconfiguring networks to be a whole lot of fun :)
And no matter how smart the peole on campus are, there will always be someone who cannot accept that someone else is more right. I have first hand experience of this since I have tunneled IPv6 at home and know pretty quickly if someone does not listen to ICMPv6 Packet Too Big -messages. Not the first time I contact people about it but so far the only one I have not been able to convince is exactly someone really smart on some campus somewhere. I wrote many emails and tried to explain that IPv6 allows MTU's as low as 1280 bytes and that ICMPv6 is a must allow protocol but nope.
Thanks for the link to that MIT packet storm postmortem. The comments thread following contains a pretty fascinating debate involving some members of the original IETF committee and RFC authors.
IPv6 is already a success in mobile and IoT, and in countries that matter in economical sense. The rest will follow automatically because they have no choice. More worrying issues are BGP and SS7 reliance in global networks, and there are no viable alternatives on the horizon.
Could you expand on these problems? Why is SS7 an issue? (Aren't telcos moving to IP based platforms? Device registration on towers can work on whatever protocol the device supports the base station encapsualtes/proxy-es/processes that further, and the telco can use whatever routing it wants internally - eg iBGP. Or even some fancy OpenFlow based control plane.) And of course the issues with BGP seem even more interesting, if you could detail those too ot'd be great.
The SS7 protocol stack is soaked with security problems, but also because it doesn't represent the modern nature of traffic. Of course, telecoms moving to IP cores and such, but SS7 still widely used mostly because of the interoperability and roaming. Positive Security recently made a summary report of the current status of the problem[1]. BGP main problem is the inherent trust to users and servers, thus allowing malicious actors or even some errors to do weird things with network traffic. See this[2] Black Hat talk quickly summarizing them.
Regarding BGP, it seems that the basic protocol and implementations are okay. ("No implementation allowed BGP OPENs with the wrong AS or from non-configured peer to reach BGP ESTABLISHED state—as a result, TCP spoofing is required to inject data", and when you can spoof TCP between routers ... it's probably too late anyway. In a peering scenario between ASes people either use a direct cable, a separate VLAN or other direct "transport", in a IXP the IXP operates a big switching fabric and the peers exchange traffic over that, but the BGP sessions use fixed IPs and basically they are fixed to switch ports, and even if currently not every IXP monitors the spoofing/abuse of those, it is easy and they should be doing so. Sure, the reality is always bleaker, but that's security. Maybe next-next-next gen will have crypto built in so far down the stack that without a shared secret no packets will flow. But then humans will just put the PSK on a bright sticker, or will continue to use "chang3me" for decades.)
The problems I heard with it is that Tier1 providers just can't really filter the routes they get from downstreams, as they'd have to know which Tier2 handles which prefixes for which clients and so on. Though I'm not convinced they are putting much effort into it, as it's easier to just plug in big Cisco boxes and set up peering with your core and your downstream customers and call it a day. (And setting up is always messy already, so it's sort of understandable that there are no easy and custom solutions for somehow verifying announcements from whatever databases.)
Even though IPv6 quickly established itself as a robust industry there are countless users who prefer the old IPv4 protocol.Even if we compare IPv6 with IPV4 there are many such positive features which makes people still choose IPv4
Ref: https://ipv4mall.com/blogs/ipv4-vs-ipv6-pros-cons/
Ah, yes, good point. Maybe forcing phones to use 3G/4G/LTE will help a bit, but using SMS and phone number as a second factor is laughable while it's completely at the mercy of a large easily soc.eng.-able company, which very-very much does not care about your SMS-sign-in security.
I don't like TOTP apps, but they are significantly better.
The weird thing is that on some countries IPv4 only turned effectively into the premium offering. This is for instance the case in Austria where you generally have the option of ipv4 or ipv6 with dslite or worse only.
All new contracts are ipv6 and the only way to get to ipv4 is via customer support. However right now ipv4 gives you the better experience.
I don't believe it's weird, in fact, I think it's natural. IPv4 is better (because every single machine and server has IPv4 connectivity, unlike IPv6) and available addresses are getting scarce. Therefore, IPv4 access with no CG-NAT is turning into a "premium" service.
Only if the end state is that the public internet will be dual-stack IPv4/IPv6 forever and everyone will need some form of IPv4 connectivity, either a real IPv4 address or NAT to one (from either private IPv4 or private IPv6). Is that the world we want? Have we solved the address space exhaustion problem if that's the route we take?
99% of users couldn't tell you what an IP address or port is let alone manually configure MACs and IPs into their router so I don't think that has anything to do with adoption of v6. To the vast majority of users they type a name in the URL bar and that's their full interaction with what they'd think of as "internet addresses".
Those administering the systems users connect to have always handled DNS just fine so I don't see why they wouldn't be able to know that the address got a bit longer.
Not really? I don't think you can reasonably argue that:
2001:db8:4242:1::2
is much harder to remember than:
203.0.113.42+192.168.1.2
In fact it's substantially fewer characters.
Okay, obviously you can pick v6 addresses such that they're long and hard to memorize, but I'd argue that if you do that and also refuse to use DNS for them then you've lost your right to complain about how long and hard to memorize they are.
We tried setting up automatic DNS records on dhcpv6 and slaac on our company lan, and we just weren't able (opnsense). We have ipv6 working, but it still doesn't "feel finished".
My university (100k students) is transitioning to ipv6. But it’s a long term roll out. I have both static ipv4 and ipv6 for my work station. They tell me the ipv4 will go away in near future.
Can anyone explain to me. So right now for v4, we have NAT, and several ways to get a port open and pointed at us. With v6, every device has its own public address, like how the internet was intended. And as sensible network admins, we should have a default deny incoming firewall policy for v6 traffic. But surely that will prevent these "end-to-end" apps from working, and now they don't even have protocols like UPnP to bypass the firewall and request ports to be opened?
I like IPv6 it can actually be easier to set up stuff instead of using IPv4 for example OSPF. But I find IPv6 is not as intuitive as IPv4 just looking at an address in IPv4 vs IPv6. You can create new networks for IPv4 pretty easily just by eyeball but not IPv6. At least I can't.
In IPv4 you might get allocated 250.250.16.0/22, and then you have to calculate in your head where exactly that begins and ends, and carefully divvy it up into partitions of different sizes.
In IPv6 you get a /56 or /48 and you know that two or four digits are wildcards. No binary math is needed, and all subnets can be the same size of /64
It's pretty easy in v6 if you follow the best practice of making client subnets /64s. Say you were assigned a bog standard /48 then you would have the patternxxxx:xxxx:xxxx:yyyy::z where:
x represents your fixed routing prefix
y represents your subnet instance (0000-FFFF, 2^16 subnets)
:: represents the expansion of "0000:"s
z represents the client identifier.
For a relatively normal /56 or /60 home user assignment via PD from an ISP you simply lose 2 or 3 "y"s respectively. In both your client netmasks are always /64 and your gateways should always be fixed:subnet::1.
It's quite a bit easier to eyeball than v4, because it's much easier to make sure that your network falls on a character boundary (multiple of 4 bits out of 128) than it is to make it fall on an octet boundary (multiple of 8 bits out of 32).
If you find v6 harder than it's just down to a lack of practice.
> "Given that fundamental constraint, there are only three basic choices for network operators:
...
3. Run native IPv6 among compatible parts of their own network with some kind of tunneling or translation (i.e., converter technologies in economics) at the boundaries to make it compatible with IPv4
Among these viable alternatives, we show that dual stack will never get us across the finish line; it is not economical. It is the third category that shows promise for some growing networks."
So, basically a more complex version of NAT is what they're proposing for the "transition" from IPv4 to 6. Am I the only one who remembers that IPv6 was supposed to eliminate NAT?
Yeah, it's fascinating here that they've gone from "NAT is bad and we won't let you implement NAT, we need an internet on a single flat 128-bit address space" to "The internet will be IPv4 forever and you should implement IPv6 internally and run NAT, because we like it better than running IPv4 NAT which is what you've done for years and works great".
That's not what the article is saying. They're saying that you still need to provide access to legacy v4-only hosts on the internet somehow, and you either do that via v4 (i.e. dual stack) or by some transition technology of which NAT64 is just one possible option.
Nobody is suggesting to not talk native v6 to the internet too, they're just suggesting to not cut your users off from v4-only services.
If all your connections are potentially NATted (i.e., any DNS lookup might only return an IPv4 record), what's the advantage? You still have to build applications that are capable of dealing with NATs / non-end-to-end connections. You just also have to maintain IPv6 infrastructure. That seems strictly worse than staying on IPv4 NAT.
(If you're talking to specific parties that you know have working IPv6, it's less work to run a site-to-site VPN than to both maintain working IPv6.)
The only world in which IPv6 is worthwhile is one in which we can turn off access to legacy v4 hosts and stop having public IPv4 addresses. At this point, it seems like there is no hope of doing so in the current Internet. Perhaps in a few hundred years the Internet itself will be dead and IPv4 will die with it, but not before then.
You throw away IPv4 internally. Nothing internally is IPv4. All your network address sizing issues vanish, puff, gone, because in IPv6 the subnets are always 64-bits, which means whether it's four boxes or four million boxes it fits in the same subnet. No more NAT, you just use real (globally unique) IPv6 addresses for everything, so there are no confusing debug sessions where you thought 10.4.5.6 was this box but actually because of how routing is set up it's _that_ box and so you wasted six hours.
So internally everything is _wonderful_
And then to manage the fact that some fraction of the Internet is (and for the foreseeable future will be) IPv4 only, you have edge devices that translate. They translate DNS too. If you ask for www.example.com and the answer is A 10.20.30.40 the edge devices wrap that inside an IPv6 address and provides that as your AAAA answer.
_This_ way around works, because 128 is bigger than 32. Unlike the people who magically want an IPv6 that hides 128-bits in 32-bits, which is mathematically impossible, this merely hides 32-bits in 128-bits, which is trivial.
Anyway, nothing else needs to even care, just those edge devices, and as transition continues you spend less and less money on them. In reality at any modern company you probably already spend more on edge devices you've added because somebody read about them in a magazine - anti-malware, service protection, next generation firewalls, that sort of thing.
The advantage is that you can be behind a dozen layers of NAT on the v4 side and it doesn't matter so much because 99% of your traffic is going over v6 anyway and anything that needs an inbound connection has the v6 available instead of being impossible. It's okay for v4 to suck if you can avoid it most of the time, but not so much when it's your only option.
Maintaining v6 is a lot less work than site-to-site VPNs, especially when "specific parties" is "random internet users" and when RFC1918 clashes are a thing.
v6 is worthwhile even if there is still some v4 going on. And even if it wasn't, how would you propose to deploy v6 and turn off v4 in one internet-wide atomic operation? There's no longer any entity that can enforce a flag day on the internet, so I can't see any way of doing that. The result is that we'd need to do a gradual changeover, which happens to be exactly what we are doing.
If a major player like GitHub doesn't support ipv6 then ??? Also a lot of vps providers do ipv6 incorrectly so some form; vultr seems to be the only one I've found that does it well.
I really want to enable ipv6 on my web site, but then I heard horror stories about connections failing if not all routers between the client and the server have ipv6 enabled.
Apparently at least for a while, browsers would not try the same request again via ipv4, so the site would simply be unreachable.
Perhaps browsers have become smarter about that, but it really makes me wary about enabling ipv6. I have no immediate benefit besides "doing the right thing", and some possible downsides.
Yes, browsers have become smarter about that. You can test it by enabling ipv6 and then drop all ipv6 packets with ip6tables, that has the same effect as if some middlebox dropped them.
IPv6 is so 90s. Put a pink lens and design a global network where are good people. Netizens as were called.
Give an IPv6 with last digits of the MAC address is unacceptable today. Unique IP per device maybe dangerous.
Today tracking exists and is smart, some organizations are logging bittorrent activity. People buys VPN, right?
Really I love shared IPv4 at my University (although they have a /16). Maybe there are thousands of devices behind. Google Ads becomes crazy. I only want privacy.
The argument seems pretty straightforward and is a classic collective action problem:
v4 isn't expensive enough (in all cost measurements) to justify switching to v6. Once that flips, when there aren't any more v4 addresses then everyone will move there.
It sounds like the costs of v6 are so high that we basically need complete saturation of the v4 IP ranges, and then a market that trades IPs at a higher friction/cost rate than than implementing v6.
v6 has dual stack, Teredo, 6to4, 6rd, 6over4, ISATAP, 6in4/4in6, NAT64/DNS64, 464xlat, DS-lite, MAP-T/E, 4rd, LW4over6... it has pretty much every possible backwards compatibility method that can work with v4.
You could make a reasonable argument that it has too many of them, even. Where did you get the idea that it didn't have backwards compatibility?
It doesn't have any backwards compatibility. You can't turn off IPv4 and just have IPv6 and still use IPv4 addresses. If it had it, you wouldn't need all those hacks.
I mean, you can call them hacks, but at the end of the day v4 uses a fixed-width 32 bit address field and has no mechanism to extend it in a way that's compatible with other v4 hosts. All you can do is hack around that. There's nothing that v6 could possibly do to avoid it, because the flaw is in the design of v4 and not in the design of v6.
Require that porn sites use only IPV6 addresses. Or provide some free benefit to people who access those sites using IPV6. I'm pretty sure adoption will surge. It worked for VHS.
The main problem is :it is too easy to ignore. You can build around all of the limitations of ipv4. Which makes ipv6 useless / not needed in the first place.
Perhaps I just misunderstand IPv6 but I prefer IPv4 with NAT and temporarily leased public router address for privacy and security reasons. AFAIK IPv6 means every device gets assigned a stable unique address everybody can identify and reach it by. And I have never seen a SOHO WiFi router that would support IPv6 anyway (perhaps latest fancy expensive ones do).
This is entirely legitimate. IPv6 is actively confusing in what "enabling" means - is there a firewall, and under what conditions are ports opened? Is there mandatory use of privacy addresses from clients, and is there any protection from clients who generate SLAAC addresses from their MAC address? Is there a NAT? (NAT66 is a thing, but very few people implement it.) The mental model of IPv4 NAT is much more straightforward and I would strongly recommend that home users prefer that.
I'm not sure what routers you've used or seen but every home router I've touched in the last 5 to 10 years has had the option to enable IPv6 in its settings.
Also, IPv6 has a unique address that everybody can reach but most if not all routers have an IPv6 firewall that gives at least if not more security than NAT provides.
> IPv6 firewall that gives at least if not more security than NAT provides
That's just not true. NAT and firewall both achieve what little security they provide through simple blocking of packets based on state information. Firewalls generally provide more robust state information, but NAT is what lets you redirect sockets. They work together.
Except NAT gives no security, because NAT doesn't block packets.
If a packet comes in that doesn't match any NAT state, then the packet isn't dropped on the floor -- it's processed as normal like any other packet would be, and in the absence of a firewall (which is logically separate, even if often implemented in the same software stack) it'll be routed to whatever the destination in the packet header is.
"If a packet comes in that doesn't match any NAT state, then the packet isn't dropped on the floor"
Yes it is, it's the same scenario as if there was no route to the destination just at a higher abstraction layer. Think about it this way: a packet just hit the NAT IP from the internet, the packet has hit it's destination. There was no NAT table match for the packet so it was not rewritten. Where would the packet be forwarded to if not the bit bucket?
It's not the same scenario at all. If there's no route to the destination then the packet will necessarily be dropped, but with no matching NAT state table entry for a packet all that happens is that the dst header field is left alone.
There will still be an IP in the dst header field! The router will still deliver the packet to that IP, subject to all the usual constraints (e.g. it needs a valid route etc). NAT won't stop that; only a firewall will.
It won't necessarily be for the router. The packet could be addressed to one of the machines on your LAN, in which case nothing NAT does will stop the router from happily forwarding it right through.
NAT does nothing to stop a router from forwarding any given packet -- and that's something that's still true regardless of what IP range you're using on the LAN side.
And in practice what that means is that the router's own IP is the destination and the packet ends up at a closed port.
Unless of course you're talking about using NAT outside the context of the RFC1918/internet boundary, in which case you're absolutely right, but that wasn't what was being discussed.
Isn't it? I thought we were talking about NAT, not about RFC1918.
Even NAT in combination with RFC1918 doesn't give you security. The use of RFC1918 would certainly limit the set of people that could connect to your LAN machines, but it would be hard to call the result secure since anybody sharing your upstream L2 network, plus your ISP and anyone who can trick, force or coerce them into cooperating could still access your network.
And what does NAT add to the situation? Certainly not any security, since any connections that were possible before you added the NAT will still be possible afterwards too. In fact a lot more connections will become possible, so it seems like it reduces the security rather than improves it.
> call the result secure since anybody sharing your upstream L2 network, plus your ISP and anyone who can trick, force or coerce them into cooperating could still access your network
Ok, so the L2 thing isn't unheard of, but otherwise these are relatively unrealistic scenarios to be concerned about, don't you think?
I guess, but the fact remains that using RFC1918 is still both more effort and less secure than just using a firewall is, and that NAT doesn't help the situation.
Do you really want the security of your network to rely on your ISP always doing the right thing for you?
Even then, that would still only put you into the situation in the second paragraph of my previous post. You would still need a firewall, and if you have a firewall then shifting to RFC1918, adding MASQ NAT or even doing both won't help, because inbound connections are already blocked.
NAT absolutely is security. It prevents naming a resource that an attacker shouldn't have access to, which is the fundamental principle behind many successful security schemes: capability models, containers / virtualization, MMUs, etc.
Sure, there are implementation flaws (as there have been in other such schemes), and sure, just clicking a NAT button and walking away doesn't get you security any more than just clicking a capability or virtualize or MMU button gets you security. But it's a powerful and solid building block, and the Internet is a better and safer place because of widespread use of NAT.
It doesn't actually do that though. If you give a machine an IP of X, and then you turn on NAT on the upstream router so that its outbound connections appear to come from Y instead, the machine is still called X.
NAT won't prevent someone from sending a packet to X, and it won't cause the router to somehow drop the packet when it sees it either. That stuff is handled by firewalls, not by NAT.
On Linux at least, NAT isn't handled by routing, it's handled by a separate layer (the firewall layer, in fact). I think that's the obvious way of implementing NAT: you're not routing at all. On the public side you're not accepting any packets not addressed to you. On the private side you're converting all packets, so you're not doing normal packet forwarding.
When packets arrive on the public side, you have to translate addresses sent to the router to convert Y to X, so you might as well drop packets that aren't sent to a valid target. I'd expect you have to go out of your way to get NAT "wrong," possibly by trying to stuff the functionality on top of actual routing. Home routers generally don't need to do actual routing ever (and if they do, they're in a non-NAT mode) so it would be surprising for them to get this wrong.
It's handled by a separate layer, yes, but that doesn't mean that the routing layer magically disappears. It's still there, and in fact it's still required to forward every single packet that goes through the router. NAT is just simply an extra layer on top that sometimes changes the addresses in the src or dst fields of some packets.
Dropping packets not sent to a valid target is called firewalling. NAT doesn't decide what's valid and what isn't; all it does is detect packets which correlate to known connections and rewrite some of the headers on those packets.
Home routers, like all routers, do a lot of routing. They sit between two networks and they forward packets between them, which is pretty much the definition of a router. Having some header rewriting going on doesn't change that.
You could, but does your device actually do so? Are you confident that 100% of the devices you own use privacy addresses and do not leak non-privacy addresses?
The nice thing about IPv4 NAT is that you plug a single gadget in to your ISP's connection (cable modem, ONT, whatever), you connect your devices to that gadget, and it works out of the box and has all the security properties you'd expect, even if you're a person who hasn't ever thought about security properties and doesn't know what IP is and is still running Windows XP because your word processor still works fine. It might be unclean, but the benefits of this model are immense.
> Are you confident that 100% of the devices you own use privacy addresses and do not leak non-privacy addresses?
I've heard stories, but I've never seen a modern operating system without privacy extensions in the wild. Maybe XP, but did XP have IPv6 enabled by default? As far as I know it didn't.
One problem with IPv4 is that each interface can only have one IP. With IPv6 an interface can have many! For example both a private and a public IP address!
I don't think its helpful to discredit all the other technical advantages of v6. Address assignment and configuration is significantly better under SLAAC than DHCP, multicasting actually makes sense, and routing logic and packet format are simplified.
If you were to try implementing a router for ipv4 and v6 the v6 one would be dramatically simplier with a lot fewer convoluted edge cases.
I actually specifically do regard (most of) v6's additional features as a bug; I think most of them could and therefore should have been implemented as separate protocols (consider ipsec, which actually did get pulled out and back ported to 4). I think the protocol we ended up with suffers from horrible second system effect and its scope creep it's part of the reason why it's taken decades to get mass adoption.
For ISPs (and mobile carriers) that are actively involved in their infrastructure, CG-NAT is more expensive to run than native ipv6 (aquiring IPv4 public addresses; tracking connection states; if all customers are on private IPv4, maintaining multiple distinct private networks with the same address space is a hassle too), so those ISPs are pushing to make services available over IPv6 (I've heard from T-Mobile USA and Jio India), but that doesn't mean they won't also run CG-NAT for customers on older devices and for services that aren't IPv6 -- it just reduces the deployment. For smaller ISPs, or where everything is contracted out, the cost savings aren't as apparent.
> it's no wonder the transition to IPv6 has stopped
Where are you getting that from? Looking at public IPv6 statistics from big companies shows that it's going up.
Google's shows a 4.5% increase in IPv6 of total traffic during the past year[0]. Facebook's shows a 6% increase and at 55% for the US [1]. Meanwhile Mexico went from 5% IPv6 to 25% this year [2].
These statistics are meaningless propaganda. What you should be interested in is the velocity of IPv6 adoption growth among ISPs and countries where adoption stopped all together, to know what to expect from actual adoption in coming years. (it's basically a failure btw)
> What you should be interested in is the velocity of IPv6 adoption growth among ISPs and countries where adoption stopped all together, to know what to expect from actual adoption in coming years. (it's basically a failure btw)
I don't understand. Are you telling me to look at how IPv6 adoption is among countries, where IPv6 usage growth has stopped? Are there any such countries?
Furthermore, I'm not sure what you mean by "actual adoption". Every statistic I look at, as referenced in my previous comment, I see IPv6 usage continuing to grow. And you're calling that "propaganda"?
Maybe we need to tax IPv4 addresses. Once again, markets suck at dealing with scarce resources. Tax externalities or ditch capitalism, you choose society!
Assuming you're not joking, the nice thing about IPv4 is that it uses 32 bits, so you can store addresses in an unsigned int and use memory efficiently. Just adding one octet takes you up to 40 bits, which has alignment issues. You may as well go up to 64 bits (half of IPv6), which could be represented as 16 hex characters, e.g. 06A4.6E1B.12C9.95C8. That way you're kicking the can much farther down the road too.
I always wish IPv6 had done example this -- use 64 bits.
The address space is still enormous: a couple billion for every currently living person (yes, I know allocating isn't 100% efficient, but even at 0.001% efficiency, that's still tens of thousands per capita).
And, the address could fit in a common word size, and be significantly more readable.
As is, IPv6's one-address-per-atom-on-Earth is unnecessary, the addresses are horrendous to read, and the collapsing colon stuff is just obnoxious.
> The address space is still enormous: a couple billion for every currently living person (yes, I know allocating isn't 100% efficient, but even at 0.001% efficiency, that's still tens of thousands per capita).
The biggest problem with IPv4 is subnetting inefficiency. IPv6 had this large address space precisely because they wanted to have smallest subnet so big that we don't have to worry about it. This is why it is told, that in IPv6 you don't allocate IP addresses, you allocate subnets.
64 bits probably wouldn't be enough to let people avoid going into address conservation mode though. Heck, there are way too many ISPs allocating a single /64 in v6 land today, and there's far more space available in v6 today than there would be after 100+ years of your 64-bit space.
Having an unnecessarily large amount of addresses is a good thing, because the alternative is to have too few addresses. You don't want to have too few addresses, because if you think v6 is taking a long time to roll out... imagine how long a replacement to it would take.
They're allocating /64s because a lot of the design of IPv6 (SLAAC, for instance) makes it easy to do one /64 per customer who would have been doing IPv4 NAT. And the rest of the world bakes assumptions around this; for instance, IPv6 spam blacklists generally operate at /64 granularity because that's assumed to be one customer, so if customers get anything smaller like /96s or even /128s, unrelated customers will share spam reputation.
In a world where we kept the IPv4 worldview of NATs and just added more addresses, a 64-address space would be fine for the same reasons that /64s are fine in IPv6 today.
And the holdup on IPv6 rollout isn't related to it being a longer address space at all.
> Heck, there are way too many ISPs allocating a single /64 in v6 land today
First, ISPs are allocating them because they can. There are enough total /64 blocks for every living person to have a couple billion blocks.
Second, ISPs are allocating /64 blocks because they have to. Well, they don't have to, but there are 20 billion billion total /64 blocks. ISPs will run of capacity in their routing tables long before address blocks are exhausted.
> Having an unnecessarily large amount of addresses is a good thing
Agreed. Both 64-bit and 128-bit have unnecessarily large address spaces. But 32-bit is too few, though, and byte/word alignment is convenient. So 64-bit is convenient, unnecessarily large solution.
There's no requirement for ISPs to allocate /64 blocks. The requirement is that they allocate enough address space for all of their client's networks to use /64s. As such, all recommendations are for /56 at least (which takes up the exact same amount of space in their routing tables as /64 does: one entry).
If v6 was 64 bits in total, then ISPs would need to be allocating something closer to /48s to users at a minimum... but can you really imagine ISPs giving /48s in a 64-bit space when many of those same ISPs don't even give something larger than /64 in a 128-bit space? And this is despite the fact that a /48-in-64-bits would be 256 networks of 256 IPs each, which is far smaller than a /56's 256 networks of 2^64 IPs each? We know from v4 that 256 IPs in a network is frequently too small.
I'm just not convinced that 64 bits is enough, and I don't think we should expend this much effort deploying something that could be too small. Sure, it might be big enough with careful management, but I think it would be stupid to take the risk.
If you were arguing for an 80 bit address space then I'd have a much harder time calling it a risk, but for some reason 80 bits is an incredibly unpopular length.
It's too small. /56 should be the minimum unless there are hard technical reasons why you can't do that. My point was that a lot of ISPs seem to think that even /63 is too big, and that's in a 128-bit address space. Surely they would be even more miserly than they currently are if you removed 99.9999..% of the address space?
I was primarily thinking of residential ISPs; business ISPs tend to be a little bit better. That said, datacenters (or rather server/VPS providers) are absolutely terrible. Most of them give you no v6 allocation of your own at all. If you're lucky they let you use as many addresses as you like on your WAN segment, but good luck if you wanted to do a VPN or routed VM subnet.
I doubt anyone cares about efficiency or I wouldn't find people storing IP addresses in JSON, as text. Unnormalized too, so IPv6 is almost guaranteed to be broken.
That's like saying towing capacity isn't important in semi's because you see boxes from Amazon that only weigh 25 lbs. Sure some random app might only deal with 25 lbs worth of efficiency problems but it's not the only piece of software that has to process IPs, such as a load balancer, home router (on underpowered CPUs), and ever increasing amounts of software networking.
Except that setting up domain names for devices in your network is out of reach for most humans, while IP addresses are trivial. My cheap router that I have to reboot nightly lets me bind an ipv4 address to every device on the network so I have known address for everything.
There is no comparable functionality for a domain name, or a subdomain or whatever. If my ISP offered free dyndns (and there was a well-adopted global standard for the service), and I could assign subdomains for each of my devices, then I could have real names for everything.
Most common routers and systems will automatically register and resolve names automatically on the local network. Plus there's zeroconf on top of that. You don't need to manually edit bind zone files for your local network unless you really want to.
I have literally never ever seen a cheap consumer router that did anything "automatically" successfully other than run DHCP and provide access from the LAN to the WAN.
The last two I've used over the last decade have automatically done this. Every machine requesting a DHCP lease is assigned "$host.lan" in the DNS service on the router, where "lan" is a default but configurable domain name.
But even if you don't have this, then zeroconf/avahi/equivalent should be giving you "$host.local".
Your cheap home router that lets you assign private IP addresses to everything could just as well be a cheap home router that serves DNS using a private TLD.
Things like Chromecast already do this for you automagically via mDNS and the .local TLD.
I am about 80% certain that in the time it took you to write this comment you could have bought a domain name, used the registrar's web-gui to input your now static IP addresses, and had a perfectly functioning DNS setup for your home.
I have a domain name. Setting up subdomains and binding it to addresses is non-trivial.
I have to figure out all the business of anames and MX records and how to set up a subdomain.
And considering that routers issue ipv4 addresses automatically, offer user-friendly GUIs for binding addresses to devices and forwarding ports, it's not really comparable is it?
You are not comparing apples to apples here. You’re talking about setting up MX records vs memorizing an IPv4 address. There is no way that pxtl@random-IPv4-address is how you’re handling your email.
If you can run a server securely on the public internet, you can set up a domain name. To pretend otherwise is a little absurd. Frankly if you can’t set up a domain properly in DNS, you probably can’t successfully manage to forward a port to your server anyway.
There are ways to solve the IPv6 problem - and ISPs in Europe have successfully rolled out both major variants, Dual Stack (Native IPv4 and v6 running alongside each other) or DSLite (Native IPv6 throughout the network, CGNat at the edge for tunnelled IPv4 traffic).
Liberty Global have opted for DSLite, the last major network of theirs will go live this year (Virgin Cable), BT and Sky (the two biggest xDSL providers) have been live for over a year at this point with Dual Stack.
To be precise this excludes 75% of all autonomous systems in the world, which is at least 75% of all ISPs plus those that connect to 25% of IPv6 capable autonomous systems, but still don't use IPv6. So we are talking like 80% of all ISPs in the world.
No, most ISPs don't. In fact they are afraid of the transition, because of the many glitches, the total lack of support of MANY devices on the consumer side, retraining helpdesk, and so many more.
I work for a large ISP and we've done our tests. We ran one about five years ago and it was a total disaster.
We're currently doing another one and we smoothed many things. Anyway it's not something welcomed by the helpdesk side. If a client with IPv6 calls with problems, the've found out that most of the times the only way to not spend lot of time with the customer is change the setup to a ppoe v4 and forget about it. And we've used competent people for this test, not you average joe with 2 prior weeks training in networking.
Helpdesk agents hate it, and the come up with very good reasons.
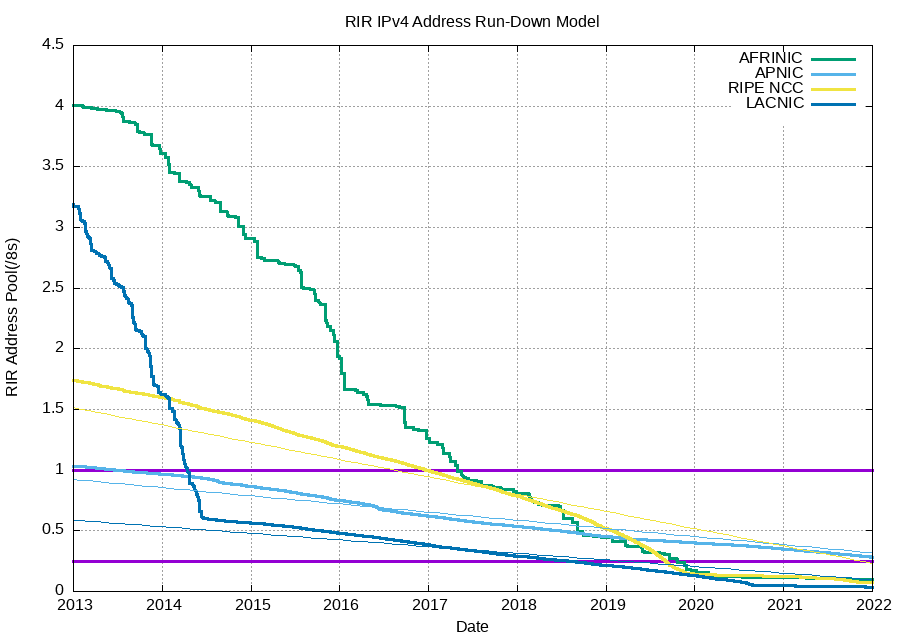{kind=link}
Coming up with a solution that looks like a huge technological advancement, with no real respect for the motivations or incentives of those who'll need to implement and use it, is a fairly common occurrence in tech and something engineers should be trained to guard against.