I'd argue that's still a lot of work to manually do. However, great work and detail, thanks a lot :-)
I'm working on a database system[1] in my spare time, which automatically retains all revisions and assignes revision timestamps during commits (single timestamp in the RevisionRootPage). Furthermore, it is tamper proof and the whole storage can be verified by comparing a single UberPage hash as in ZFS.
Basically it is a persistent trie-based revision index (plus document and secondary indexes) mapped to durable storage, a simple log-structured append-only file. A second file tracks revision offsets to provide binary search on an in-memory map of timestamps. As the root of the tree is atomically swapped it does not need a WAL, which basically is another data file and can be omitted in this case.
Besides versioning the data itself in a binary encoding similar to BSON it tracks changes and writes simple JSON diff files for each new revision.
The data pages are furthermore not simply copied on write, but a sliding snapshot algorithm makes sure, that only changed records mainly have to be written. Before the page fragments are written on durable storage they are furthermore compressed and in the future might be encrypted.
You might like what we're doing with Splitgraph. Our command line tool (sgr) installs an audit log into Postgres to track changes [0]. Then `sgr commit` can write these changes to delta-compressed objects [1], where each object is a columnar fragment of data, addressable by the LTHash of rows added/deleted by the fragment, and attached to metadata describing its index [2].
I haven't explored sirix before, but at first glance it looks like we have some similar ideas — thanks for sharing, I'm excited to learn more, especially about its application of ZFS.
In order to provide fast audits of subtrees, the system stores optionally a merkle hash tree (a hash in each node) and updates the hashes for all ancestors automatically during updates.
Every google hit for "UberPage" seems to be your writing, is there standard ZFS
terminology that would be found in ZFS documentation to what you're referring?
It's in our case the tree root of the index, which is always written after all the descendant pages have been written as a new revision is committed (during a postorder traversal of the new pages).
In ZFS the UberPage is called UberBlock. We borrowed some of the concepts as to add checksums in the parent pages instead of the pages itself. In ZFS they are blocks :-)
True. In general I could add storing relational data as well, but currently I'm entirely focusing on JSON and auto-indexing for secondary indexes as well higher order function support in Brackit.
Of course we'd need more man-power as I'm more or less the only one working on the core in my spare time (since 2012).
Moshe mainly works on the clients and a frontend. A new frontend based on SolidJS is in the works showing the history and diffs as in
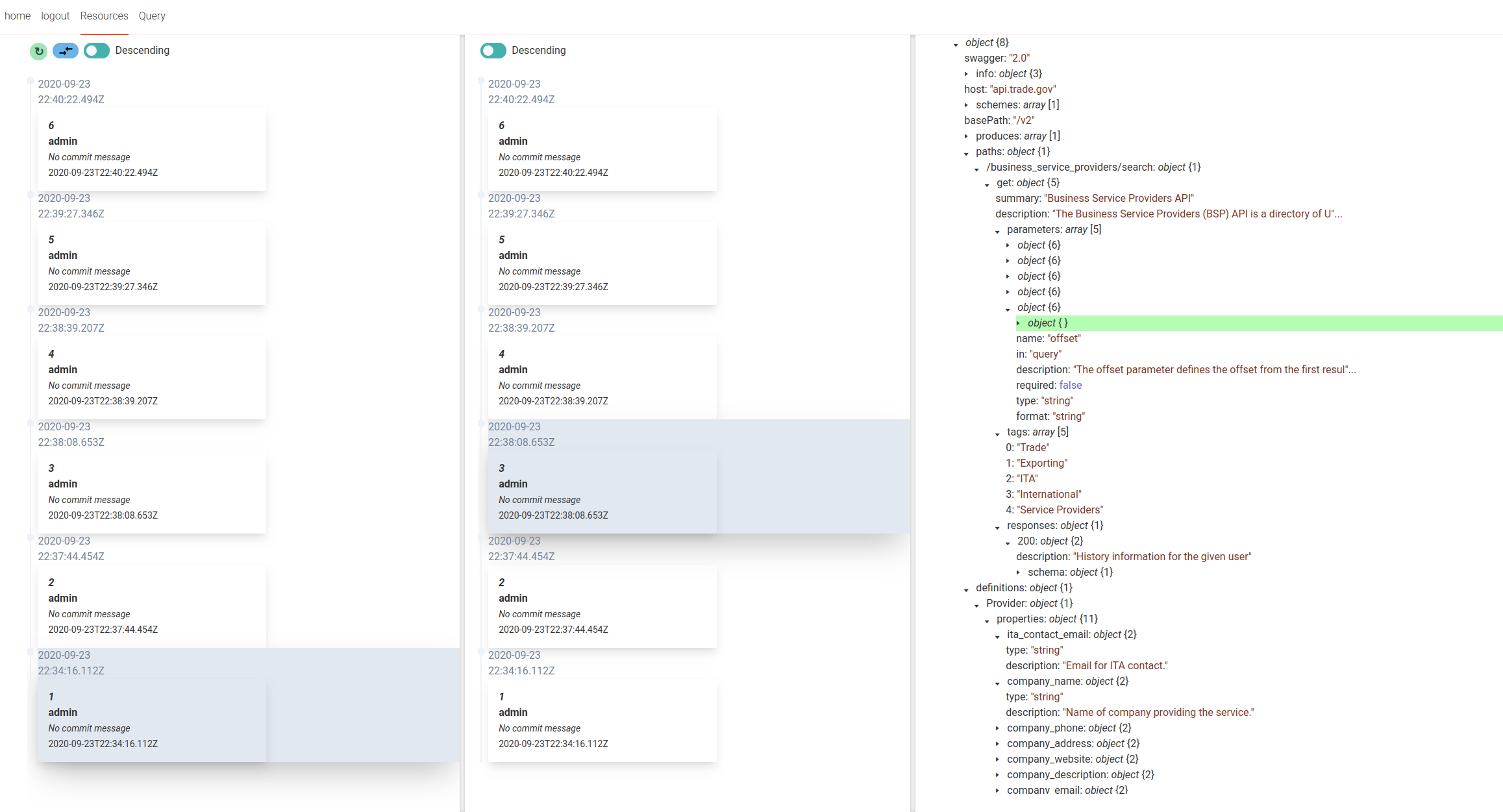{kind=link}
I'm working on a database system[1] in my spare time, which automatically retains all revisions and assignes revision timestamps during commits (single timestamp in the RevisionRootPage). Furthermore, it is tamper proof and the whole storage can be verified by comparing a single UberPage hash as in ZFS.
Basically it is a persistent trie-based revision index (plus document and secondary indexes) mapped to durable storage, a simple log-structured append-only file. A second file tracks revision offsets to provide binary search on an in-memory map of timestamps. As the root of the tree is atomically swapped it does not need a WAL, which basically is another data file and can be omitted in this case.
Besides versioning the data itself in a binary encoding similar to BSON it tracks changes and writes simple JSON diff files for each new revision.
The data pages are furthermore not simply copied on write, but a sliding snapshot algorithm makes sure, that only changed records mainly have to be written. Before the page fragments are written on durable storage they are furthermore compressed and in the future might be encrypted.
[1] https://sirix.io | https://github.com/sirixdb/sirix